A medida que las aplicaciones blockchain escalan, los datos en cadena se han convertido en un recurso fundamental para DeFi, el análisis en cadena, agentes de IA y las aplicaciones multicadena. Sin embargo, los datos sin procesar de la blockchain suelen presentarse en forma de bloques, transacciones y registros de eventos, lo que obliga a los desarrolladores a pasar por complejos procesos de extracción y procesamiento antes de poder utilizarlos. Por eso, acceder de forma eficiente a los datos en cadena se ha vuelto un desafío clave en el desarrollo de infraestructura Web3.
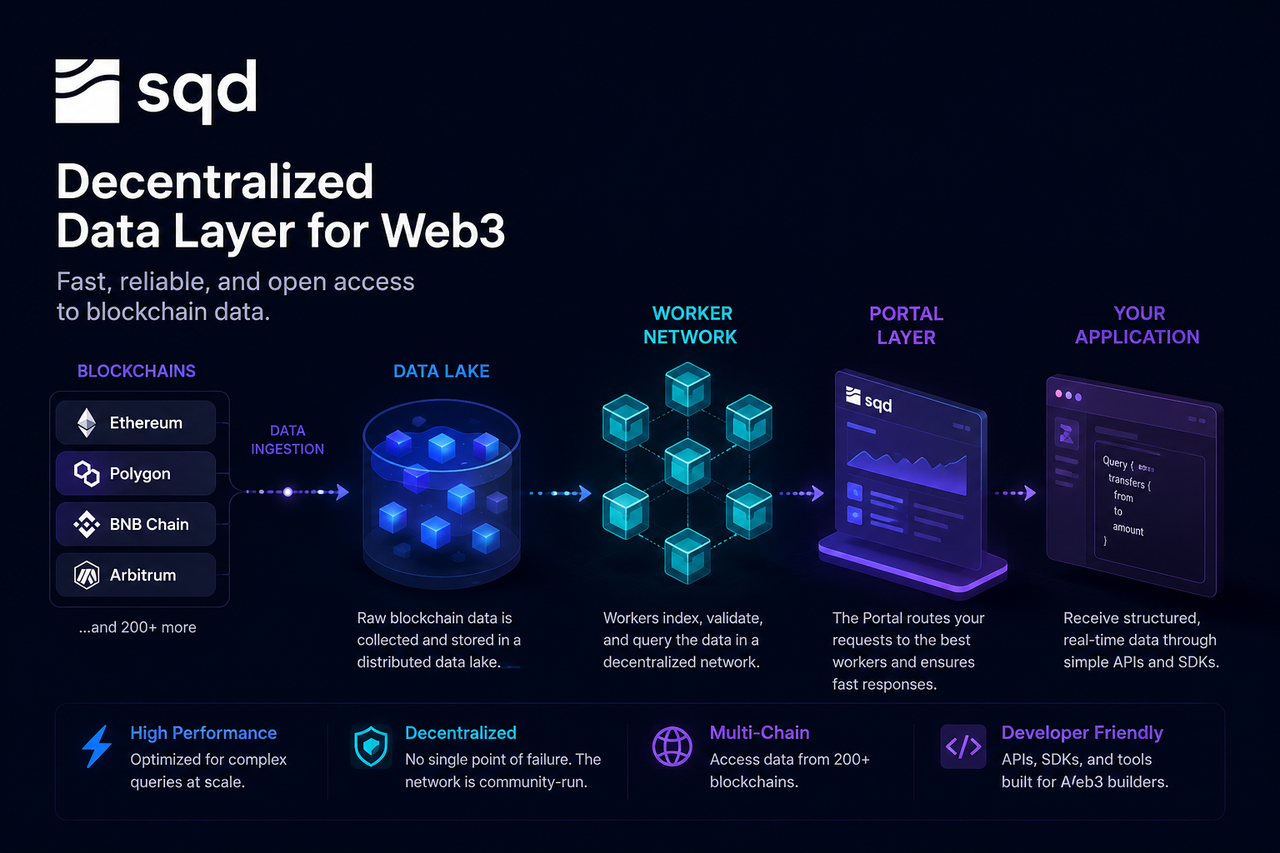
Subsquid (SQD) surge como una red de datos descentralizada diseñada para resolver este problema. A diferencia de los nodos RPC tradicionales, que leen directamente el estado de la cadena, SQD ofrece una arquitectura de servicio de datos construida en torno a un lago de datos, nodos Worker y una capa de consulta Portal. Esto permite a los desarrolladores acceder a datos en cadena estructurados e indexados a través de una interfaz unificada.
¿Qué es una consulta de datos SQD?
Una consulta de datos SQD es el proceso mediante el cual los desarrolladores recuperan datos en cadena a través de la red SQD. En lugar de solicitar los datos directamente a los nodos blockchain, las consultas SQD devuelven datos ya preprocesados e indexados, lo que permite respuestas rápidas a solicitudes complejas.
Por ejemplo, un panel de DeFi podría necesitar agregar volúmenes de negociación de los últimos meses; un agente de IA podría necesitar leer cambios de activos en varias direcciones; y una plataforma de análisis podría necesitar consultar todo el historial de eventos de un contrato inteligente concreto. Todos estos son escenarios típicos de consulta de datos.
La idea central de SQD es externalizar el procesamiento pesado de datos por adelantado, para que las aplicaciones puedan acceder directamente a datos estructurados sin tener que manejar grandes volúmenes de datos de bloques sin procesar.
Cómo entran los datos en cadena en la red SQD
El punto de partida de una consulta ocurre en realidad antes de que el desarrollador envíe la solicitud.
A medida que las redes blockchain generan nuevos bloques de forma constante, la red SQD captura datos sin procesar (bloques, transacciones, eventos de registro y cambios de estado de contratos inteligentes) en tiempo real a través de su sistema de recolección de datos. Estos datos se estandarizan para su posterior procesamiento y almacenamiento.
Como SQD admite múltiples blockchains, su capa de recolección de datos debe sincronizar continuamente flujos de datos de diferentes ecosistemas, garantizando la integridad y consistencia de los datos. Tras la estandarización, los datos se escriben en la capa de almacenamiento de la red.
El lago de datos es la infraestructura de almacenamiento central en la red SQD.
A diferencia de las bases de datos tradicionales diseñadas para datos estructurados, un lago de datos puede manejar grandes cantidades de datos sin procesar y semiestructurados. En esta capa se almacenan el historial de la blockchain, los datos de transacciones, los registros de eventos y las instantáneas de estado.
La ventaja de un lago de datos es que conserva el historial completo de datos y, al mismo tiempo, permite un procesamiento y análisis posteriores flexibles. Para aplicaciones que necesitan rastrear millones de transacciones, este método de almacenamiento es mucho más eficiente que consultar directamente los nodos blockchain.
El lago de datos actúa como la memoria a largo plazo de la red SQD, proporcionando datos para la indexación y consultas posteriores.
Cómo procesan los nodos Worker las solicitudes de consulta
Los nodos Worker son la capa de ejecución en la red SQD.
Cuando los datos entran en la red, los nodos Worker los indexan, clasifican y optimizan para una recuperación rápida. El proceso de indexación es como crear un índice para una enciclopedia enorme: no es necesario escanear todo desde cero para cada consulta.
Además de construir índices, los nodos Worker ejecutan tareas de consulta. Cuando un desarrollador solicita datos específicos, un nodo Worker localiza rápidamente los registros relevantes usando el índice, y luego filtra, agrega y calcula los resultados.
Como varios nodos Worker pueden ejecutarse en paralelo, la red puede manejar muchas consultas simultáneamente, lo que mejora el rendimiento general y la escalabilidad.
Cómo recibe Portal las solicitudes de los desarrolladores
Portal es el punto de entrada unificado para que los desarrolladores accedan a la red SQD.
Los desarrolladores suelen enviar consultas a través de una API o SDK sin conectarse directamente a los nodos subyacentes. Cuando una solicitud llega a Portal, el sistema analiza la consulta y determina qué nodos Worker son los más adecuados para manejarla.
Portal actúa como un balanceador de carga en internet. Los desarrolladores solo interactúan con una única interfaz, mientras que la compleja programación de recursos y la selección de nodos ocurren automáticamente en segundo plano.
Este diseño simplifica el desarrollo y mejora la eficiencia general de recursos de la red.
Cómo se devuelven los resultados de las consultas a las aplicaciones
Una vez que los nodos Worker terminan de procesar, los resultados se envían de vuelta a la capa Portal.
Portal formatea los resultados según sea necesario y envía los datos finales a la aplicación. Los desarrolladores reciben datos ya estructurados (por ejemplo, objetos JSON o resultados analíticos) listos para su visualización en pantalla, lógica de negocio o inferencia de IA.
Todo el proceso suele ser transparente para los usuarios finales. Simplemente ven cargar la página o aparecer los resultados del análisis, mientras que en segundo plano ya se han ejecutado múltiples pasos, desde la recolección de datos hasta la ejecución de la consulta.
Cómo Hotblocks admite consultas de datos en tiempo real
Además de las consultas históricas, muchas aplicaciones necesitan información en cadena en tiempo real.
Por ejemplo, los sistemas de monitoreo en cadena necesitan detectar transacciones anómalas, las estrategias automatizadas necesitan escuchar eventos de contratos inteligentes y los agentes de IA necesitan estar al tanto de las condiciones más recientes del mercado. Estos escenarios requieren que los datos estén disponibles tan pronto como se produce un nuevo bloque.
Hotblocks es la capa de datos en tiempo real que SQD proporciona, diseñada específicamente para nuevos bloques y eventos en vivo. En comparación con los datos históricos del lago de datos, Hotblocks se centra en la baja latencia y las respuestas rápidas, lo que permite a los desarrolladores crear aplicaciones en tiempo real.
En qué se diferencian las consultas SQD de las consultas RPC tradicionales
Ambos métodos pueden acceder a datos en cadena, pero la lógica subyacente es muy diferente.
Los nodos RPC tradicionales son como consultar directamente una base de datos blockchain. Cada solicitud debe buscar los datos correspondientes a partir del estado en cadena o de los registros históricos. A medida que el alcance de la consulta crece, la presión sobre el rendimiento y los costes aumenta en consecuencia.
SQD, en cambio, utiliza una arquitectura preindexada. Los datos ya están organizados e indexados cuando entran en la red, por lo que las consultas no necesitan escanear todo el historial de nuevo. Para análisis complejos, agregación de datos multicadena y estadísticas históricas a largo plazo, SQD suele ofrecer una eficiencia mucho mayor.
| Dimensión |
SQD |
RPC tradicional |
| Fuente de datos |
Datos preindexados |
Lecturas en cadena en tiempo real |
| Eficiencia de consulta |
Alta |
Media |
| Análisis de datos históricos |
Ventaja significativa |
Más complejo |
| Soporte multicadena |
Fuerte |
Depende de múltiples nodos |
| Coste de infraestructura |
Menor |
Mayor |
| Lectura de estado en tiempo real |
Compatible |
Compatible |
Por qué el proceso de consulta SQD es importante para los agentes de IA
Los agentes de IA se están convirtiendo en una aplicación clave en la infraestructura Web3, y el acceso a los datos es fundamental para su funcionamiento.
Si un agente de IA necesita analizar el comportamiento de una billetera, rastrear estados de protocolos o ejecutar acciones en cadena, debe obtener continuamente datos precisos y estructurados. Las consultas RPC tradicionales pueden proporcionar datos sin procesar, pero normalmente requieren procesamiento y transformación adicionales.
La interfaz de datos unificada que ofrece SQD reduce la complejidad para que los agentes de IA obtengan información en cadena. Con resultados de consulta estandarizados, los sistemas de IA pueden dedicar más potencia de cómputo al análisis y la toma de decisiones, en lugar de a la manipulación de datos.
A medida que la IA y Web3 continúan convergiendo, la importancia de las capas de datos descentralizadas no hará más que crecer.
Resumen
Una consulta de datos SQD no es solo una simple lectura de datos: es un flujo de trabajo completo que involucra la capa de recolección de datos, el lago de datos, los nodos Worker y la capa Portal, todos trabajando juntos. Los datos blockchain sin procesar se recopilan y almacenan primero, luego se indexan y optimizan, y finalmente se entregan a los desarrolladores a través de una interfaz unificada.
Este modelo de procesamiento distribuido preindexado permite que SQD ofrezca una alta eficiencia para consultas complejas, análisis multicadena y acceso a datos en tiempo real. A medida que DeFi, las plataformas de análisis en cadena y los agentes de IA demandan cada vez más datos, la arquitectura de capa de datos representada por SQD se está convirtiendo en una parte esencial de la infraestructura Web3.
Preguntas frecuentes
¿Cuál es la diferencia entre una consulta de datos SQD y una consulta API normal?
Una API normal suele ser mantenida por un proveedor centralizado, mientras que una consulta SQD se ejecuta en una red de datos descentralizada. Los datos SQD provienen de sistemas de recolección e indexación en cadena, ofreciendo un acceso a datos más abierto y verificable.
¿Por qué la velocidad de consulta de SQD es más rápida que la de algunas solicitudes RPC?
SQD completa la indexación y organización por adelantado, por lo que las consultas no necesitan reescanear grandes cantidades de historial de bloques. Para tareas de análisis complejo y datos históricos, SQD es generalmente mucho más rápido.
¿Qué función cumplen los nodos Worker en el proceso de consulta?
Los nodos Worker se encargan de la indexación, el filtrado, la agregación y el cálculo. Cuando Portal recibe una solicitud de consulta, los nodos Worker relevantes realizan el procesamiento real de los datos.
¿Cuál es la diferencia entre un lago de datos y una base de datos?
Una base de datos normalmente almacena datos estructurados, mientras que un lago de datos puede almacenar grandes volúmenes de datos sin procesar y semiestructurados. SQD utiliza un lago de datos para almacenar el historial completo en cadena, lo que permite consultas y análisis flexibles.
¿Puede Hotblocks reemplazar las consultas de datos históricos?
No. Hotblocks está diseñado para el acceso a datos en tiempo real; las consultas históricas todavía dependen del lago de datos y del sistema de indexación. Juntos, forman la capacidad completa de servicios de datos de SQD.
¿Qué aplicaciones son las más adecuadas para los servicios de consulta SQD?
Los paneles de DeFi, los exploradores de blockchain, las plataformas de análisis en cadena, los sistemas de monitoreo en tiempo real, las aplicaciones multicadena y los agentes de IA (cualquier escenario que necesite acceso frecuente a datos en cadena) son ideales para los servicios de consulta SQD.








