Básico
Spot
Opera con criptomonedas libremente
Margen
Multiplica tus beneficios con el apalancamiento
Convertir e Inversión automática
0 Fees
Opera cualquier volumen sin tarifas ni deslizamiento
ETF
Obtén exposición a posiciones apalancadas de forma sencilla
Trading premercado
Opera nuevos tokens antes de su listado
Contrato
Accede a cientos de contratos perpetuos
CFD
Oro
Plataforma global de activos tradicionales
Opciones
Hot
Opera con opciones estándar al estilo europeo
Cuenta unificada
Maximiza la eficacia de tu capital
Trading de prueba
Introducción al trading de futuros
Prepárate para operar con futuros
Eventos de futuros
Únete a eventos para ganar recompensas
Trading de prueba
Usa fondos virtuales para probar el trading sin asumir riesgos
Lanzamiento
CandyDrop
Acumula golosinas para ganar airdrops
Launchpool
Staking rápido, ¡gana nuevos tokens con potencial!
HODLer Airdrop
Holdea GT y consigue airdrops enormes gratis
Pre-IPOs
Accede al acceso completo a las OPV de acciones globales
Puntos Alpha
Opera activos on-chain y recibe airdrops
Puntos de futuros
Gana puntos de futuros y reclama recompensas de airdrop
Inversión
Simple Earn
Genera intereses con los tokens inactivos
Inversión automática
Invierte automáticamente de forma regular
Inversión dual
Aprovecha la volatilidad del mercado
Staking flexible
Gana recompensas con el staking flexible
Préstamo de criptomonedas
0 Fees
Usa tu cripto como garantía y pide otra en préstamo
Centro de préstamos
Centro de préstamos integral
Centro de patrimonio VIP
Planes de aumento patrimonial prémium
Gestión patrimonial privada
Asignación de activos prémium
Quant Fund
Estrategias cuantitativas de alto nivel
Staking
Haz staking de criptomonedas para ganar en productos PoS
Apalancamiento inteligente
Apalancamiento sin liquidación
Acuñación de GUSD
Acuña GUSD y gana rentabilidad de RWA
Promociones
Centro de actividades
Únete a actividades y gana recompensas
Referido
20 USDT
Invita amigos y gana por tus referidos
Programa de afiliados
Gana recompensas de comisión exclusivas
Gate Booster
Aumenta tu influencia y gana airdrops
Anuncio
Novedades de plataforma en tiempo real
Gate Blog
Artículos del sector de las criptomonedas
Servicios VIP
Grandes descuentos en tarifas
Gestión de activos
Solución integral para la gestión de activos
Institucional
Soluciones de activos digitales: empresas
Desarrolladores (API)
Conecta con el ecosistema de aplicaciones Gate
Transferencia bancaria OTC
Deposita y retira fiat
Programa de bróker
Reembolsos generosos mediante API
AI
Gate AI
Tu compañero de IA conversacional para todo
Gate AI Bot
Usa Gate AI directamente en tu aplicación social
GateClaw
Gate Blue Lobster, listo para usar
Gate for AI Agent
Infraestructura de IA, Gate MCP, Skills y CLI
Gate Skills Hub
+10 000 habilidades
De la oficina al trading, una biblioteca de habilidades todo en uno para sacar el máximo partido a la IA
GateRouter
Elige inteligentemente entre más de 40 modelos de IA, con 0% de costos adicionales
La IA todavía no puede vencer al ingeniero de guardia: aquí está el por qué
En resumen
Las empresas de IA siguen promoviendo agentes autónomos de ingenieros de confiabilidad del sitio—IA que investiga incidentes de producción en lugar de humanos. Datadog realizó el benchmark real en fallos reales, y los mejores modelos de IA aún no pueden superar a los ingenieros que se supone deben reemplazar. El benchmark es ARFBench (Marco de Referencia para Razonamiento de Anomalías), un proyecto conjunto de Datadog y Carnegie Mellon. Construido a partir de 63 incidentes reales de producción, extraídos de los propios hilos de Slack de los ingenieros durante emergencias en vivo—750 preguntas de opción múltiple que cubren 142 métricas de monitoreo y 5.38 millones de puntos de datos, cada pregunta verificada manualmente. Sin datos sintéticos. Sin escenarios de libro de texto. “Trillones de dólares se pierden cada año debido a fallos en los sistemas”, escriben los investigadores. El benchmark evalúa si la IA puede realmente ayudar a cambiar eso.
“A pesar del papel central de este análisis basado en preguntas en la respuesta a incidentes, aún no está claro si los modelos de base modernos pueden responder de manera confiable a los tipos de preguntas de series temporales que los ingenieros plantean en la práctica”, dice el documento. Las preguntas se dividen en tres niveles. Nivel I: ¿Existe una anomalía en este gráfico? Nivel II: ¿Cuándo empezó, qué tan severa es, qué tipo? El Nivel III—el más difícil—requiere razonamiento entre métricas: ¿Este gráfico está causando el problema en ese otro gráfico? Ahí es donde la IA se desmorona. GPT-5 obtiene solo un 47.5% de F1 en preguntas de Nivel III, una métrica que penaliza a los modelos por manipular las respuestas eligiendo la clase más común.
“Despite the central role of such question-driven analysis in incident response, it remains unclear whether modern foundation models can reliably answer the kinds of time series questions engineers ask in practice,” the researchers write. Cómo se compararon todos los modelos GPT-5 lideró todos los modelos existentes con un 62.7% de precisión—en una prueba donde adivinar al azar obtiene un 24.5%. Gemini 3 Pro obtuvo un 58.1%. Claude Opus 4.6: 54.8%. Claude Sonnet 4.5: 47.2%. Los expertos en la materia alcanzaron un 72.7% de precisión. Los no expertos—investigadores de series temporales en Datadog sin experiencia extensa en observabilidad—llegaron a un 69.7%. Ningún modelo de IA superó a ninguno de los dos niveles de referencia humana.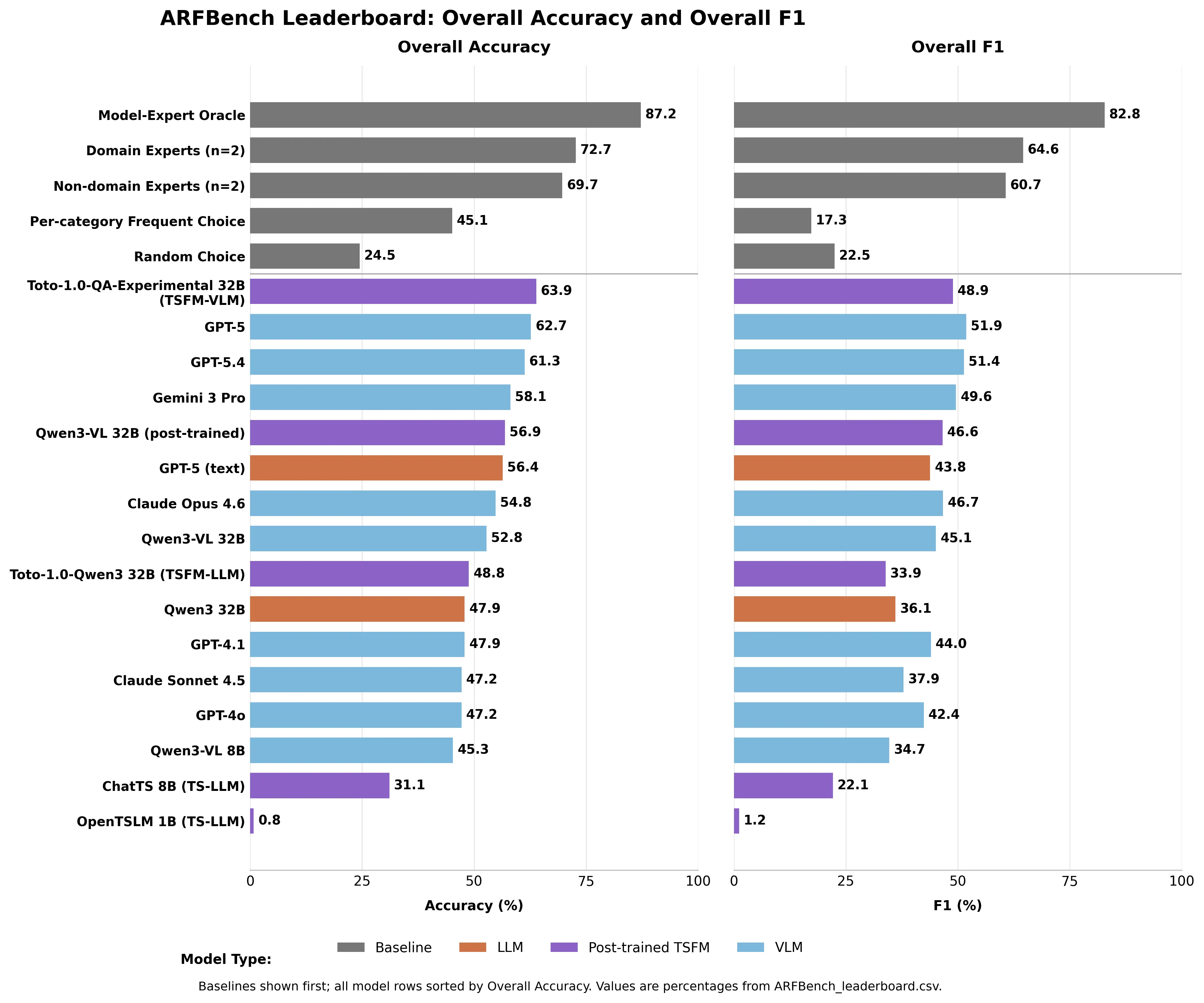
Imagen creada por Decrypt basada en el CSV del leaderboard de ARFBench
El modelo que realmente encabezó toda la clasificación fue el híbrido propio de Datadog: Toto—su modelo interno de pronóstico de series temporales—combinado con Qwen3-VL 32B. Toto-1.0-QA-Experimental alcanzó un 63.9% de precisión, superando a GPT-5 con menos parámetros. En identificación de anomalías específicamente, superó a todos los demás modelos en al menos 8.8 puntos porcentuales en F1. Un modelo de dominio diseñado específicamente, entrenado con datos de observabilidad, superando a un sistema de propósito general en esta tarea específica, es el resultado esperado. Esa es la idea. El hallazgo más valioso no es qué modelo obtuvo la puntuación más alta. “Observamos perfiles de error sustancialmente diferentes entre los modelos líderes y los expertos humanos, lo que sugiere que sus fortalezas son complementarias”, escriben los investigadores. Los modelos hallucinan, omiten metadatos y pierden contexto de dominio. Los humanos malinterpretan marcas de tiempo precisas y ocasionalmente fallan en instrucciones complejas. Los errores apenas se superponen.
Modela un “Modelo-Experto Oracle” teórico—un juez perfecto que siempre elige la respuesta correcta entre la IA y el humano—y obtienes un 87.2% de precisión y un 82.8% de F1. Muy por encima de cualquiera solo. Eso no es un producto. Es un objetivo documentado—construido a partir de emergencias reales, no de conjuntos de datos curados—que cuantifica exactamente cuánto mejor podría ser la colaboración humano-IA. El leaderboard está en vivo en Hugging Face. GPT-5 tiene un 62.7%. El techo es 87.2%.