L'essor de l'intelligence artificielle redessine l'industrie mondiale des semi-conducteurs. Avec l'accélération de la demande en grands modèles de langage, en IA générative et en calcul haute performance, le volume de données que les puces de calcul doivent traiter croît de manière exponentielle. Dans ce contexte, les technologies de mémoire traditionnelles atteignent leurs limites en matière de bande passante et d'efficacité énergétique, tandis que la HBM (High Bandwidth Memory – mémoire à large bande passante), qui permet un transfert de données ultra-rapide, s'impose comme un pilier de l'infrastructure IA.
Sur le marché mondial de la HBM, SK Hynix occupe une position prépondérante. En tant que l'un des premiers fabricants mondiaux de puces mémoire, SK Hynix possède non seulement une expertise approfondie dans la DRAM, mais a également pris une avance précoce dans le développement et la production en série de produits HBM. Alors que les GPU d'IA exigent des mémoires toujours plus rapides, SK Hynix est devenu un fournisseur clé dans la chaîne d'approvisionnement des puces mémoire pour l'IA.
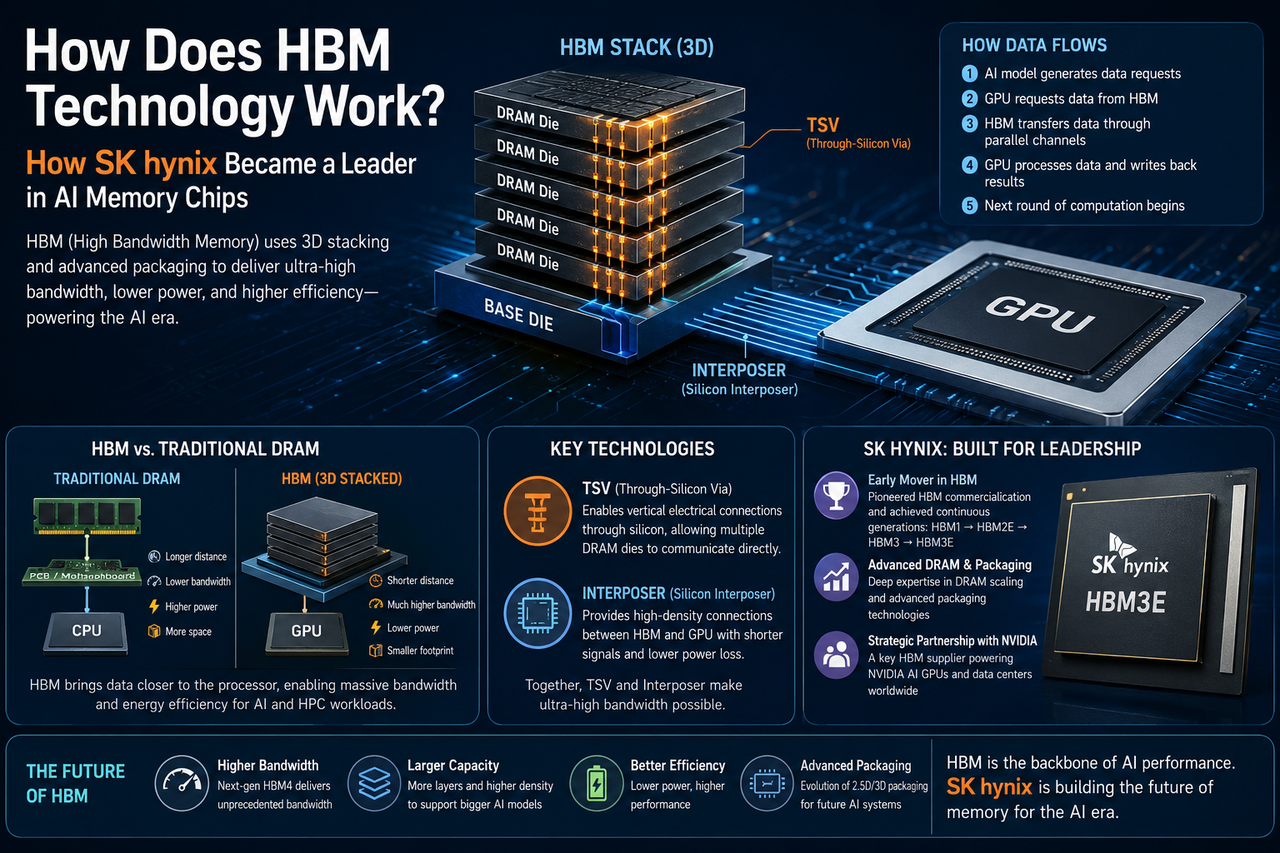
Qu'est-ce que la HBM ?
La HBM (High Bandwidth Memory) est une technologie de mémoire à large bande passante, spécialement conçue pour l'IA, le calcul haute performance (HPC), les centres de données et le traitement graphique. Par rapport à la DRAM traditionnelle, la HBM offre un débit de données bien supérieur dans un espace beaucoup plus réduit.
L'innovation clé de la HBM réside dans son architecture d'empilement 3D, où plusieurs puces DRAM sont empilées verticalement et interconnectées à haute vitesse via la technologie TSV (Through-Silicon Via – technologie de traversée de silicium). Les données parcourant des distances plus courtes, la HBM augmente considérablement la bande passante tout en réduisant la consommation d'énergie.
Pourquoi la DRAM traditionnelle ne suffit plus pour l'IA
Pendant des années, la DRAM traditionnelle a été la solution mémoire de référence pour les ordinateurs et les serveurs. Mais les exigences en données de l'ère de l'IA ont largement dépassé celles de l'informatique conventionnelle.
Lors de l'entraînement de grands modèles, les GPU doivent lire et écrire en permanence un nombre colossal de paramètres. Si les données ne peuvent pas être acheminées assez rapidement pour alimenter le GPU, même les processeurs les plus puissants perdent des cycles en attente.
La DRAM traditionnelle est confrontée aux limitations suivantes :
| Défi |
Performance de la DRAM traditionnelle |
| Plafond de bande passante |
Débit de données limité |
| Consommation électrique élevée |
Chemins de données plus longs augmentant la consommation d'énergie |
| Encombrement physique important |
Difficile à intégrer dans des déploiements denses |
| Passage à l'échelle pour l'IA |
Efficacité réduite dans les configurations multi-GPU |
C'est pourquoi l'industrie s'est tournée vers de nouvelles architectures mémoire mieux adaptées à l'IA, et la HBM a connu un essor considérable.
L'idée centrale de la HBM : raccourcir la distance que les données doivent parcourir et augmenter considérablement le nombre de canaux de données.
La DRAM traditionnelle est connectée au processeur via la carte mère. La HBM, en revanche, est emballée directement à côté du GPU. Plusieurs puces DRAM sont empilées verticalement à l'aide de la technologie TSV, et un interposeur en silicium les relie au GPU pour une communication à ultra-haute bande passante.
Le flux de données se déroule comme suit :
- Un modèle d'IA exécuté sur le GPU génère un flux constant de demandes de données.
- Le GPU envoie des commandes de lecture à la HBM.
- La HBM renvoie les données via plusieurs canaux parallèles à une vitesse fulgurante.
- Une fois le calcul terminé, le GPU écrit les résultats en mémoire.
- Le cycle de calcul suivant commence immédiatement.
Cette conception minimise la latence due au déplacement des données et améliore considérablement l'efficacité de l'entraînement de l'IA.
HBM vs. DRAM traditionnelle : différences structurelles
| Dimension |
HBM |
DRAM traditionnelle |
| Architecture de la puce |
Empilée en 3D |
Agencement planaire |
| Interconnexion de données |
TSV + interposeur |
Pistes PCB |
| Bande passante |
Ultra-haute |
Modérée |
| Consommation électrique |
Plus faible |
Plus élevée |
| Cas d'utilisation principaux |
IA, GPU, HPC |
PC, serveurs |
Pourquoi la TSV et l'interposeur sont essentiels
La TSV (Through-Silicon Via) est la technologie qui permet l'empilement 3D de la HBM. Elle crée des canaux verticaux à travers la puce, permettant aux couches de mémoire empilées de communiquer directement entre elles. L'interposeur (interposeur en silicium) sert de pont de connexion entre le GPU et la HBM, offrant des voies de données beaucoup plus denses et une perte de signal plus faible que les pistes de carte mère traditionnelles.
Ensemble, ces deux technologies constituent l'épine dorsale de l'architecture HBM et expliquent pourquoi elle peut atteindre une bande passante aussi extrême.
Rôle de la HBM dans l'entraînement de l'IA
Les modèles d'IA modernes contiennent des milliards, voire des trillions de paramètres. Chaque session d'entraînement nécessite la lecture de vastes ensembles de données.
Si le GPU calcule plus vite que les données ne peuvent être fournies, le système subit une sous-utilisation de sa puissance de calcul. Le rôle de la HBM est de maintenir le pipeline de données plein, garantissant ainsi le fonctionnement du GPU à son efficacité maximale.
Dans l'inférence IA, la HBM est tout aussi cruciale. Un accès rapide à la mémoire accélère les temps de réponse et améliore les performances du modèle. C'est pourquoi la HBM est devenue un élément indispensable de la conception des puces IA.
SK Hynix possède des racines profondes dans la technologie DRAM, qui ont jeté les bases de ses avancées en matière de HBM.
L'entreprise a été parmi les premières à commercialiser la HBM. De la HBM1 à la HBM3E, SK Hynix n'a cessé de repousser les limites en matière de bande passante, de capacité, d'efficacité énergétique et de packaging avancé.

Avant l'engouement pour l'IA, le marché de la HBM était relativement de niche. Pourtant, SK Hynix a continué à investir dans la R&D. Lorsque l'IA générative et les grands modèles ont fait exploser la demande, l'entreprise disposait déjà d'une technologie mature et d'une capacité de production prêtes à l'emploi.
Ce positionnement stratégique à long terme a conféré à SK Hynix un avantage concurrentiel redoutable.
SK Hynix et NVIDIA : un partenariat stratégique
Les GPU d'IA constituent le plus grand marché d'application pour la HBM, et NVIDIA est un acteur majeur dans le domaine des puces IA.
Les GPU d'IA haut de gamme actuels nécessitent des sous-systèmes mémoire massifs à large bande passante. La HBM est devenue la norme pour les GPU haut de gamme, et SK Hynix en est un fournisseur clé.
Cette relation permet à SK Hynix de jouer un rôle central dans la construction de l'infrastructure IA, renforçant ainsi son importance stratégique dans la chaîne d'approvisionnement mondiale des semi-conducteurs.
L'avenir de la HBM
Alors que les modèles d'IA continuent de croître, la technologie HBM évolue également.
Principales tendances à venir :
| Direction technologique |
Objectif |
| HBM4 |
Bande passante et capacité encore plus élevées |
| Davantage de couches empilées |
Densité mémoire accrue |
| Packaging avancé |
Latence et consommation réduites |
| Mémoire optimisée pour l'IA |
Meilleure efficacité d'entraînement |
| Intégration chiplet |
Amélioration de l'évolutivité système |
À l'avenir, les gains de performance des puces IA ne dépendront pas seulement du GPU lui-même, mais de plus en plus de l'innovation en matière de mémoire.
HBM vs. GDDR : quelles différences ?
La HBM et la GDDR sont toutes deux des mémoires haute performance, mais elles sont conçues pour des tâches différentes.
La GDDR est conçue pour les cartes graphiques grand public, augmentant la vitesse via des fréquences d'horloge plus élevées. La HBM, quant à elle, atteint ses performances grâce à un bus ultra-large et à un empilement vertical, offrant une bande passante plus élevée et une consommation d'énergie plus faible. Dans l'entraînement IA, le HPC et les centres de données, la HBM présente généralement un avantage net.
Résumé
La HBM est l'une des technologies mémoire les plus importantes de l'ère de l'IA. Grâce à l'empilement 3D, aux TSV et aux interposeurs en silicium, elle offre une bande passante qui dépasse de loin celle de la DRAM traditionnelle. Alors que l'entraînement de grands modèles et le calcul haute performance exigent toujours plus, la HBM est devenue indispensable pour les GPU IA et l'infrastructure des centres de données.
Grâce à des décennies d'expertise en DRAM, à des compétences avancées en packaging et à un investissement constant dans la HBM, SK Hynix s'est imposé comme un leader mondial. Des puces IA aux centres de données, des GPU aux supercalculateurs, la HBM alimente la croissance du calcul IA, et SK Hynix se trouve au cœur de cette chaîne d'approvisionnement critique.
FAQ
Pourquoi la HBM est-elle meilleure pour l'IA que la DRAM traditionnelle ?
La HBM offre une bande passante beaucoup plus élevée, une latence plus faible et une consommation d'énergie réduite. L'entraînement des modèles d'IA nécessite la lecture constante d'ensembles de données volumineux, ce qui fait de la HBM un choix bien mieux adapté aux besoins mémoire des GPU.
Qu'est-ce que la technologie TSV ?
La TSV (Through-Silicon Via) crée des connexions électriques verticales à travers les puces empilées. La HBM utilise la TSV pour réaliser un packaging 3D dense.
Quelle est la différence entre la HBM et la GDDR ?
La GDDR est conçue pour le rendu graphique ; la HBM est conçue pour l'IA, le HPC et les centres de données. La HBM offre généralement une bande passante et une efficacité énergétique supérieures.
Pourquoi SK Hynix est-il leader sur le marché de la HBM ?
SK Hynix a investi très tôt dans la HBM et possède une expertise approfondie dans la fabrication de DRAM et le packaging avancé. Lorsque la demande en IA a explosé, l'entreprise disposait de produits matures et d'une capacité de production prête à monter en échelle.
Que changera la HBM4 ?
La HBM4 devrait repousser encore plus loin la bande passante, la capacité et l'efficacité énergétique, prenant en charge des charges de travail d'entraînement IA plus importantes. Alors que le calcul IA continue de croître, la HBM4 devrait devenir une solution mémoire importante pour les plates-formes haute performance de nouvelle génération.








