DeepSeek lanzó versiones preliminares de DeepSeek-V4-Pro y DeepSeek-V4-Flash el 24 de abril de 2026, ambos modelos de pesos abiertos con ventanas de contexto de un millón de tokens y precios significativamente inferiores a alternativas occidentales comparables. El modelo V4-Pro cuesta $1.74 por un millón de tokens de entrada y $3.48 por un millón de tokens de salida—aproximadamente 1/20 del precio de Claude Opus 4.7 y un 98% menos que GPT-5.5 Pro, según las especificaciones oficiales de la compañía.
Arquitectura del modelo y escala
DeepSeek-V4-Pro presenta 1.6 billones de parámetros totales, lo que lo convierte en el modelo de código abierto más grande en el mercado de LLM hasta la fecha. Sin embargo, solo se activan 49 mil millones de parámetros por cada pasada de inferencia, usando lo que DeepSeek llama el enfoque Mixture-of-Experts, perfeccionado desde V3. Este diseño permite que el modelo completo permanezca inactivo mientras solo se activan los fragmentos relevantes para cualquier solicitud dada, reduciendo los costos de cómputo mientras mantiene la capacidad de conocimiento.
DeepSeek-V4-Flash opera a una escala menor con 284 mil millones de parámetros totales y 13 mil millones de parámetros activos. Según los benchmarks de DeepSeek, “alcanza un rendimiento de razonamiento comparable al de la versión Pro cuando se le da un presupuesto de pensamiento mayor”.
Ambos modelos admiten un millón de tokens de contexto como característica estándar—aproximadamente 750,000 palabras, o aproximadamente toda la trilogía de “El Señor de los Anillos” más texto adicional.
Innovación técnica: mecanismos de atención a escala
DeepSeek abordó el problema de escalado computacional inherente al procesamiento de contextos largos al inventar dos nuevos tipos de atención, según se detalla en el documento técnico de la compañía disponible en GitHub.
Los mecanismos estándar de atención en IA enfrentan un problema de escalado brutal: cada vez que la longitud del contexto se duplica, el costo de cómputo aumenta aproximadamente en cuatro. La solución de DeepSeek implica dos enfoques complementarios:
Compressed Sparse Attention funciona en dos pasos. Primero comprime grupos de tokens—por ejemplo, cada 4 tokens—en una sola entrada. Luego, en lugar de atender a todas las entradas comprimidas, usa un “Lightning Indexer” para seleccionar solo los resultados más relevantes para cualquier consulta dada. Esto reduce el alcance de atención del modelo de un millón de tokens a un conjunto mucho más pequeño de fragmentos importantes.
Heavily Compressed Attention adopta un enfoque más agresivo, colapsando cada 128 tokens en una sola entrada sin selección dispersa. Aunque pierde detalle de grano fino, proporciona una vista global extremadamente barata. Los dos tipos de atención se ejecutan en capas alternadas, permitiendo que el modelo mantenga tanto el detalle como la visión general.
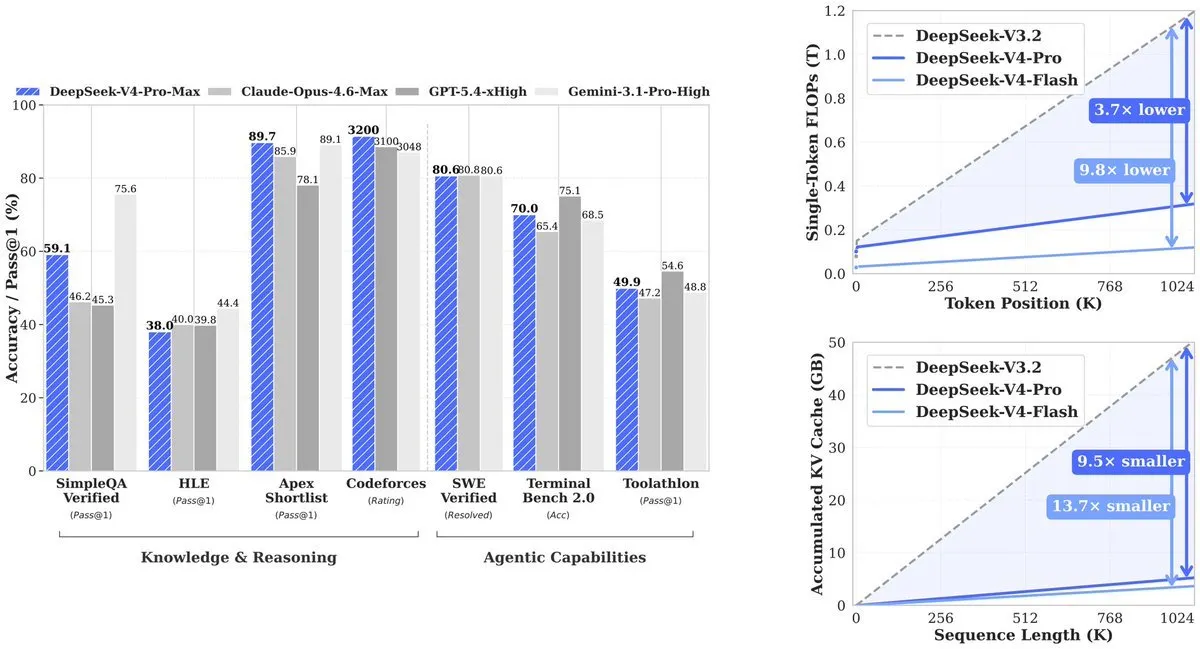
El resultado: V4-Pro usa 27% del cómputo que su predecesor (V3.2) requería. La KV cache—la memoria necesaria para rastrear el contexto—baja a 10% de V3.2. V4-Flash impulsa aún más la eficiencia: 10% de cómputo y 7% de memoria en comparación con V3.2.
Rendimiento en benchmarks y posición competitiva
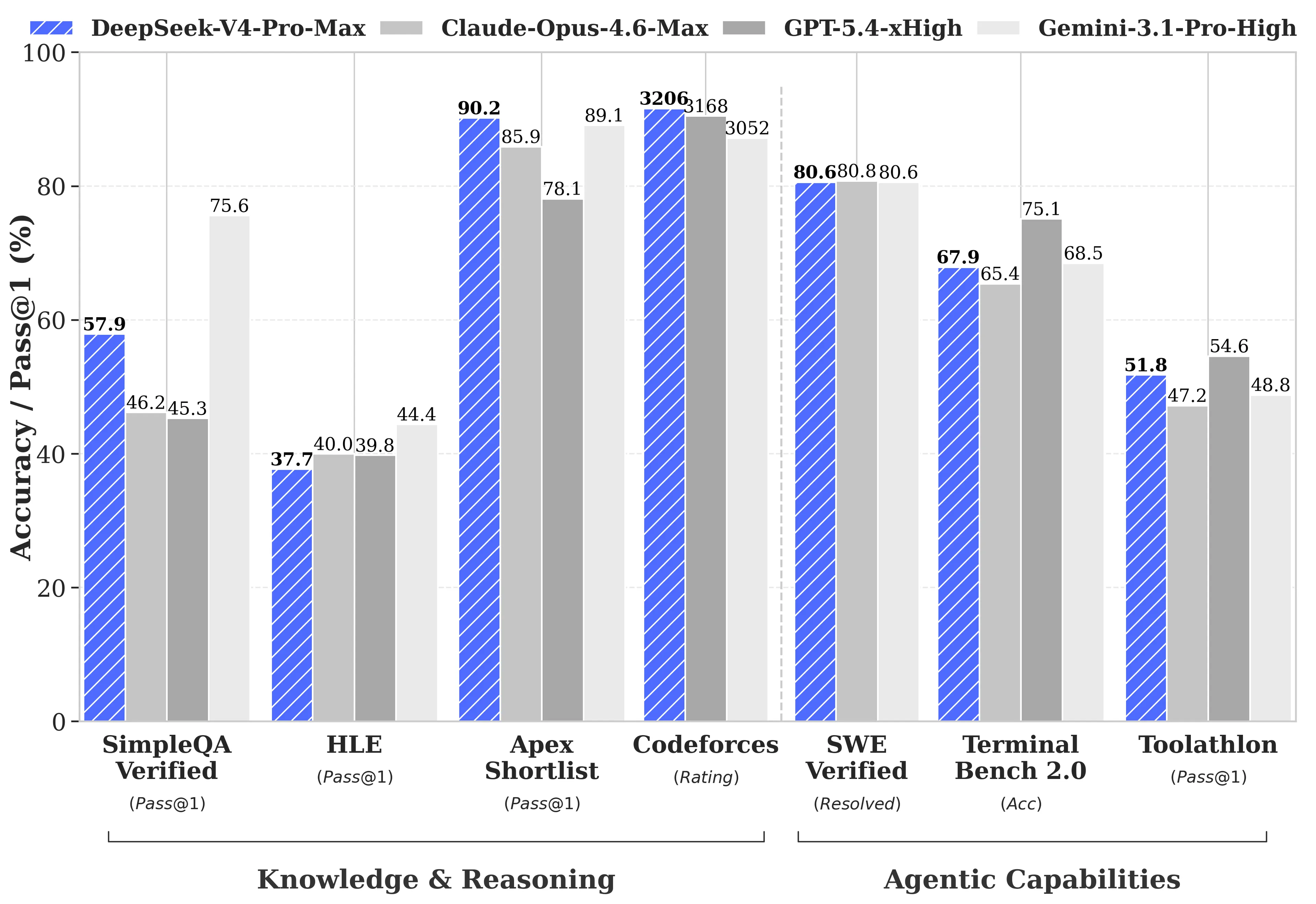
DeepSeek publicó comparaciones de benchmarks exhaustivas contra GPT-5.4 y Gemini-3.1-Pro, incluyendo áreas en las que V4-Pro queda por detrás de los competidores. En tareas de razonamiento, el razonamiento de V4-Pro se queda atrás frente a GPT-5.4 y Gemini-3.1-Pro por aproximadamente tres a seis meses, según el informe técnico de DeepSeek.
Donde V4-Pro lidera:
- Codeforces (programación competitiva): V4-Pro obtuvo 3,206, colocándolo alrededor del puesto 23 entre participantes reales de concursos humanos
- Apex Shortlist (problemas de matemáticas y STEM curados): 90.2% de tasa de aprobación frente a 85.9% de Opus 4.6 y 78.1% de GPT-5.4
- SWE-Verified (resolución de issues en GitHub): 80.6%, igualando a Claude Opus 4.6
Donde V4-Pro queda por detrás:
- MMLU-Pro (multitarea): Gemini-3.1-Pro con 91.0% frente a V4-Pro con 87.5%
- GPQA Diamond (conocimiento experto): Gemini con 94.3 frente a V4-Pro con 90.1
- Humanity's Last Exam (nivel de posgrado): Gemini-3.1-Pro con 44.4% frente a V4-Pro con 37.7%
En tareas de contexto largo, V4-Pro lidera a los modelos de código abierto y supera a Gemini-3.1-Pro en CorpusQA (simulando análisis real de documentos con un millón de tokens) pero pierde frente a Claude Opus 4.6 en MRCR, que mide la recuperación de información específica enterrada profundamente en texto largo.
Capacidades de agentes y de codificación
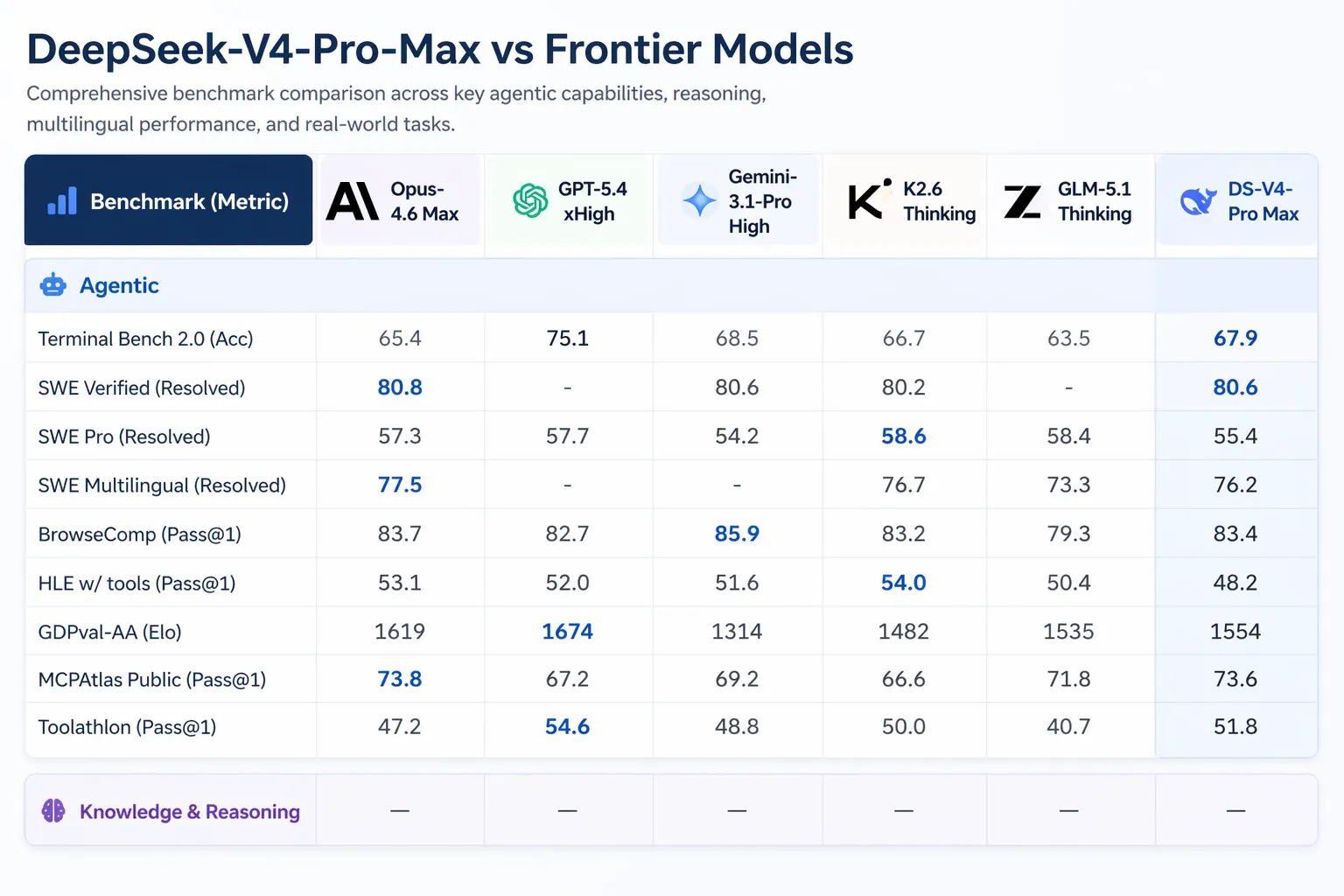
V4-Pro puede ejecutarse en Claude Code, OpenCode y otras herramientas de codificación de IA. Según la encuesta interna de DeepSeek a 85 desarrolladores que usaron V4-Pro como su agente de codificación principal, el 52% dijo que estaba listo para ser su modelo predeterminado, el 39% se inclinó por que sí, y menos del 9% dijo que no. Las pruebas internas de DeepSeek indicaron que V4-Pro supera a Claude Sonnet y se acerca a Claude Opus 4.5 en tareas de codificación orientadas a agentes.
Artificial Analysis colocó a V4-Pro primero entre todos los modelos con pesos abiertos en GDPval-AA, un benchmark que prueba trabajo de conocimiento valioso económicamente en tareas de finanzas, legales e investigación. V4-Pro-Max obtuvo 1,554 Elo, por delante de GLM-5.1 (1,535) y MixinMax's M2.7 (1,514). Claude Opus 4.6 obtiene 1,619 en el mismo benchmark.
V4 introduce el “pensamiento intercalado”, que conserva toda la cadena de pensamiento a través de llamadas a herramientas. En modelos previos, cuando un agente hacía múltiples llamadas a herramientas—como buscar en la web, ejecutar código y luego volver a buscar—el contexto de razonamiento del modelo se vaciaba entre rondas. V4 mantiene la continuidad del razonamiento entre pasos, evitando la pérdida de contexto en flujos de trabajo automatizados complejos.
Panorama competitivo y contexto de precios
El lanzamiento de V4 llega en medio de una actividad significativa en el espacio de la IA. Anthropic envió Claude Opus 4.7 el 16 de abril de 2026. GPT-5.5 de OpenAI se lanzó el 23 de abril de 2026, con GPT-5.5 Pro con precios de $30 por un millón de tokens de entrada y $180 por un millón de tokens de salida. GPT-5.5 supera a V4-Pro en Terminal Bench 2.0 (82.7% frente a 70.0%), que prueba flujos de trabajo de agentes de línea de comandos complejos.
Xiaomi lanzó MiMo V2.5 Pro el 22 de abril de 2026, ofreciendo capacidades multimodales completas (imagen, audio, video) a $1 entrada y $3 salida por millón de tokens. Tencent lanzó Hy3 el mismo día que GPT-5.5.
Para tener perspectiva de precios: el CEO de Cline, Saoud Rizwan, señaló que si Uber hubiera usado DeepSeek en lugar de Claude, su presupuesto de IA de 2026—presuntamente suficiente para cuatro meses de uso—habría durado siete años.
Despliegue y disponibilidad
Tanto V4-Pro como V4-Flash tienen licencia MIT y están disponibles en Hugging Face. Por ahora, los modelos son solo texto; DeepSeek indicó que está trabajando en capacidades multimodales. Ambos modelos pueden ejecutarse gratis en hardware local o personalizarse según las necesidades de la compañía.
Los endpoints existentes deepseek-chat y deepseek-reasoner de DeepSeek ya enrutan a V4-Flash en modos sin pensamiento y con pensamiento, respectivamente. Los antiguos endpoints deepseek-chat y deepseek-reasoner se retirarán el 24 de julio de 2026.
DeepSeek entrenó parte de V4 usando chips Huawei Ascend, eludiendo las restricciones de exportación de EE. UU. La compañía indicó que, una vez que 950 supernodos nuevos entren en línea más adelante en 2026, el precio ya bajo del modelo Pro bajará aún más.
Implicaciones prácticas
Para las empresas, la estructura de precios puede cambiar los cálculos costo-beneficio. Un modelo que lidera benchmarks de código abierto a $1.74 por un millón de tokens de entrada hace que el procesamiento a gran escala de documentos, la revisión legal y las canalizaciones de generación de código sean sustancialmente más baratos que seis meses antes. El contexto de un millón de tokens permite que bases de código completas o presentaciones regulatorias se procesen en una sola solicitud en lugar de fragmentarse en múltiples llamadas.
Para desarrolladores y creadores independientes, V4-Flash es la consideración principal. A $0.14 de entrada y $0.28 de salida por millón de tokens, es más barato que los modelos que se consideraban opciones de presupuesto hace un año, mientras maneja la mayoría de tareas que gestiona la versión Pro.

