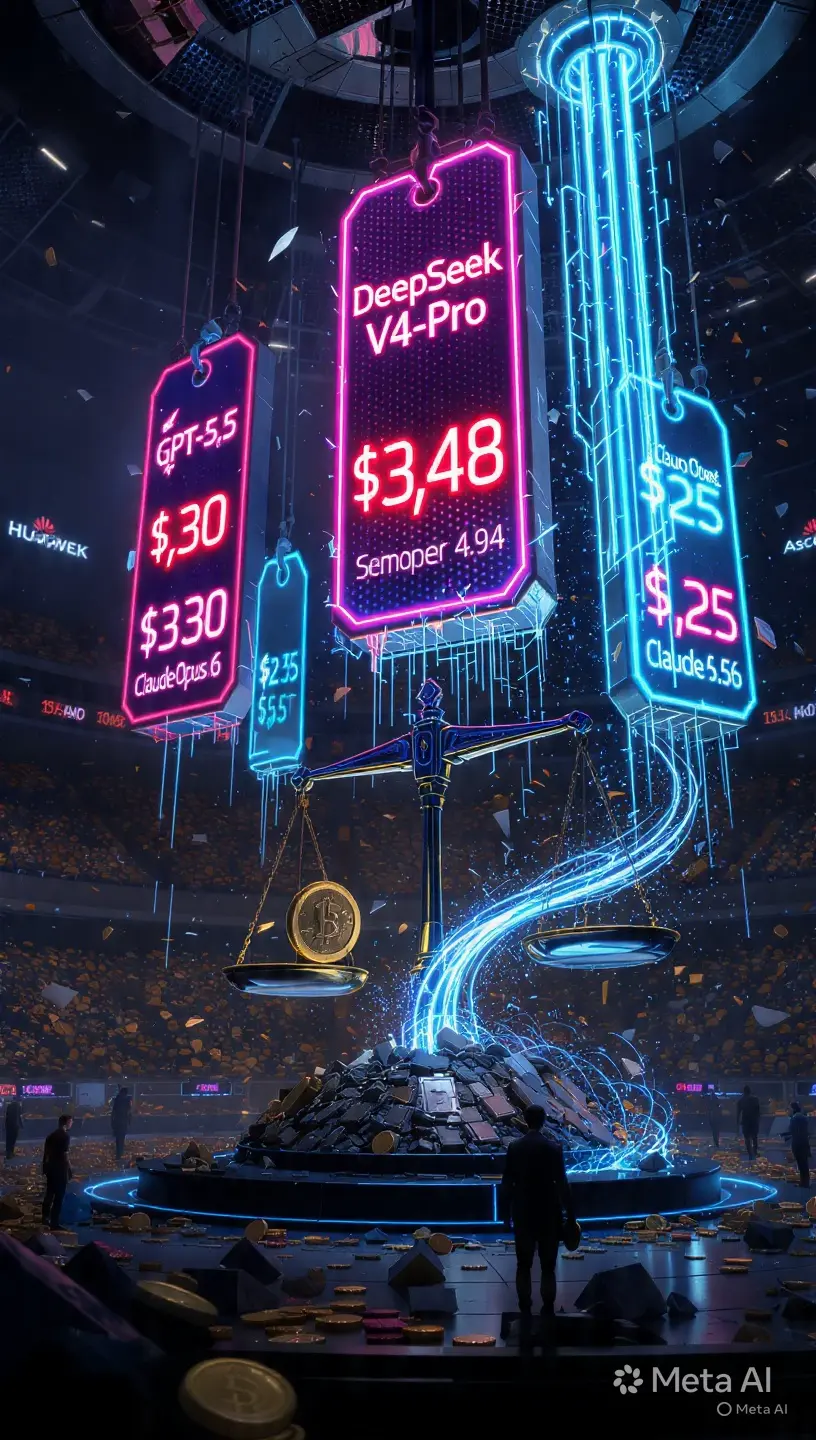#GateSquareDaily #Deepseek #AIPriceWar #AIAgents
La guerra de precios de IA se intensifica
DeepSeek’s V4 reduce los precios del mercado, y los efectos en cadena ya se están mostrando
Una nueva frontera acaba de abrirse en la carrera de IA, y no se trata de puntos de referencia. Se trata de precios.
El 24 de abril de 2026, DeepSeek, con sede en Hangzhou, lanzó versiones preliminares de su familia de modelos V4: V4-Pro y V4-Flash. Ambos son de peso abierto, licenciados por MIT y soportan una ventana de contexto de 1 millón de tokens. Sin embargo, el titular es el costo.
1. ¿Qué tan agresivo es el recorte?
La fijación de precios de la API de DeepSeek establece el piso para modelos de clase frontera:
• V4-Flash: $0.14 por millón de tokens de entrada, $0.28 por millón de tokens de salida • V4-Pro: $1.74 por millón de tokens de entrada, $3.48 por millón de tokens de salida
Comparado con los líderes actuales en EE. UU.: GPT-5.5 tiene un precio de $5 entrada / $30 salida por millón de tokens, mientras que Claude Opus 4.6 funciona a $25 por millón de tokens de salida. Gemini 3.1 Pro se sitúa en $2 entrada / $12 salida.
En términos simples: V4-Pro cuesta aproximadamente una séptima parte de Claude Opus 4.6 y casi una novena parte de GPT-5.5 en tokens de salida. V4-Flash es 12.4 veces más barato que Pro, mientras que solo le sigue en 1.6 puntos en SWE-bench Verified. Para los desarrolladores, esa es la diferencia entre un presupuesto de IA de 4 meses que dura 7 años con el mismo nivel de uso.
La compañía dijo que V4-Pro “igualaba a los modelos líderes en varias áreas” y mejoraba las capacidades de los agentes para tareas de múltiples pasos. Pruebas independientes sitúan a V4-Pro en un 80.6% en SWE-bench Verified, a 0.2 puntos de Claude Opus 4.6. Lidera en LiveCodeBench con un 93.5%.
2. Por qué esto importa: Tres puntos de presión
La adopción podría acelerarse
A $0.28 por millón de tokens de salida, V4-Flash hace viables casos de uso de alto volumen: procesamiento de documentos, análisis de bases de código, bucles de agentes. Las startups que estaban fuera del alcance de razonamiento de clase GPT-5 ahora pueden ejecutar cargas de trabajo de producción por 1/10 del costo. El contexto de 1 millón de tokens significa que repositorios de código completos o presentaciones legales caben en una sola solicitud.
Rivales enfrentan compresión de márgenes
Los laboratorios occidentales ya están aumentando precios y limitando el uso para gestionar la demanda. La medida de DeepSeek obliga a tomar una decisión: reducir precios y comprimir márgenes, o ceder la cuota de mercado de desarrolladores. La brecha de precios no es del 10% o 20%, sino de 7 a 9 veces en salida. Para las empresas que construyen flujos de trabajo con agentes, el costo por token ahora es un ítem de línea, no un error de redondeo.
Las narrativas de IA ganan impulso, incluyendo la IA en cripto
La inferencia barata cambia la economía de los agentes de IA. Si puedes ejecutar un modelo de 1.6 billones de parámetros por $3.48 por millón de tokens de salida, los agentes en cadena, las redes de inferencia descentralizadas y los proyectos de tokens de IA de repente tienen un camino hacia costos unitarios sostenibles. V4 está licenciado por MIT y es de peso abierto, lo que significa que cualquiera con GPUs puede alojarlo por sí mismo. Eso elimina el bloqueo del proveedor y se alinea con la tesis de composabilidad de las criptomonedas.
El hardware también forma parte de la historia. Huawei anunció soporte completo para V4 en sus chips Ascend 950 el mismo día. DeepSeek validó el modelo tanto en GPUs Nvidia como en NPUs Huawei Ascend. La compañía dijo que los precios de Pro podrían caer drásticamente una vez que los supernodos Ascend 950 se desplieguen a escala en la segunda mitad de 2026. Una pila de IA doméstica china — modelos más chips — reduce aún más los costos y disminuye la dependencia del hardware estadounidense.
3. Los compromisos
V4-Pro no es el mejor en todo. En SWE-bench Pro, que mide la ingeniería de software en el mundo real, Opus 4.7 lidera con un 64.3% frente a V4-Pro con un 55.4%. En tareas de razonamiento profundo, GPT-5.5 todavía tiene ventaja. DeepSeek reconoce que “las limitaciones en la capacidad de computación de alto nivel” están restringiendo el rendimiento de Pro en su lanzamiento.
Y hay un contexto regulatorio: el Departamento de Estado de EE. UU. advirtió globalmente sobre la supuesta destilación china de modelos de IA estadounidenses un día antes del lanzamiento de V4. OpenAI y Anthropic han acusado a DeepSeek de destilar sus modelos. DeepSeek no ha respondido a esas acusaciones.
4. Qué pasa después
1. Pilotos empresariales: Se espera que los CFO vuelvan a ejecutar modelos de ROI. Si V4-Pro entrega el 95% de la capacidad por el 10% del costo, “suficiente” será la opción ganadora para muchas tareas. 2. Impulso de código abierto: Con 1.6 billones de parámetros, licencia MIT y pesos de Hugging Face, V4 se convierte en el modelo abierto más grande disponible. La afinación y los despliegues privados serán más fáciles. 3. Diversificación del hardware: El soporte completo para Ascend indica que la pila de IA de China está madurando. Si Huawei produce en volumen, los desarrolladores chinos podrán construir sin Nvidia. 4. Respuesta de precios: Observa a OpenAI, Anthropic y Google. Mantener el precio mientras un modelo abierto alcanza un 80.6% en SWE-bench a 1/9 del costo no es un equilibrio estable.
Esta es una guerra de precios, pero también un cambio de estrategia. DeepSeek V4 no afirma superar a GPT-5.5 o Claude Opus 4.7 en todos los puntos de referencia. Afirma estar lo suficientemente cerca, ser abierto y mucho más barato. Durante los últimos dos años, la suposición era que los modelos frontera requerían presupuestos frontera. V4 rompe ese vínculo.
Si la adopción sigue el precio, entonces la demanda de inferencia, el uso de agentes y las aplicaciones integradas de IA — incluidos los tokens de IA en cripto — se expandirán. Los competidores tendrán que responder en costo, no solo en capacidad. Y la narrativa de que la IA avanzada debe ejecutarse en chips estadounidenses acaba de tener un contraejemplo.
La guerra de IA ya no se trata solo de quién tiene el modelo más inteligente. Se trata de quién hace que la inteligencia sea asequible.
La guerra de precios de IA se intensifica
DeepSeek’s V4 reduce los precios del mercado, y los efectos en cadena ya se están mostrando
Una nueva frontera acaba de abrirse en la carrera de IA, y no se trata de puntos de referencia. Se trata de precios.
El 24 de abril de 2026, DeepSeek, con sede en Hangzhou, lanzó versiones preliminares de su familia de modelos V4: V4-Pro y V4-Flash. Ambos son de peso abierto, licenciados por MIT y soportan una ventana de contexto de 1 millón de tokens. Sin embargo, el titular es el costo.
1. ¿Qué tan agresivo es el recorte?
La fijación de precios de la API de DeepSeek establece el piso para modelos de clase frontera:
• V4-Flash: $0.14 por millón de tokens de entrada, $0.28 por millón de tokens de salida • V4-Pro: $1.74 por millón de tokens de entrada, $3.48 por millón de tokens de salida
Comparado con los líderes actuales en EE. UU.: GPT-5.5 tiene un precio de $5 entrada / $30 salida por millón de tokens, mientras que Claude Opus 4.6 funciona a $25 por millón de tokens de salida. Gemini 3.1 Pro se sitúa en $2 entrada / $12 salida.
En términos simples: V4-Pro cuesta aproximadamente una séptima parte de Claude Opus 4.6 y casi una novena parte de GPT-5.5 en tokens de salida. V4-Flash es 12.4 veces más barato que Pro, mientras que solo le sigue en 1.6 puntos en SWE-bench Verified. Para los desarrolladores, esa es la diferencia entre un presupuesto de IA de 4 meses que dura 7 años con el mismo nivel de uso.
La compañía dijo que V4-Pro “igualaba a los modelos líderes en varias áreas” y mejoraba las capacidades de los agentes para tareas de múltiples pasos. Pruebas independientes sitúan a V4-Pro en un 80.6% en SWE-bench Verified, a 0.2 puntos de Claude Opus 4.6. Lidera en LiveCodeBench con un 93.5%.
2. Por qué esto importa: Tres puntos de presión
La adopción podría acelerarse
A $0.28 por millón de tokens de salida, V4-Flash hace viables casos de uso de alto volumen: procesamiento de documentos, análisis de bases de código, bucles de agentes. Las startups que estaban fuera del alcance de razonamiento de clase GPT-5 ahora pueden ejecutar cargas de trabajo de producción por 1/10 del costo. El contexto de 1 millón de tokens significa que repositorios de código completos o presentaciones legales caben en una sola solicitud.
Rivales enfrentan compresión de márgenes
Los laboratorios occidentales ya están aumentando precios y limitando el uso para gestionar la demanda. La medida de DeepSeek obliga a tomar una decisión: reducir precios y comprimir márgenes, o ceder la cuota de mercado de desarrolladores. La brecha de precios no es del 10% o 20%, sino de 7 a 9 veces en salida. Para las empresas que construyen flujos de trabajo con agentes, el costo por token ahora es un ítem de línea, no un error de redondeo.
Las narrativas de IA ganan impulso, incluyendo la IA en cripto
La inferencia barata cambia la economía de los agentes de IA. Si puedes ejecutar un modelo de 1.6 billones de parámetros por $3.48 por millón de tokens de salida, los agentes en cadena, las redes de inferencia descentralizadas y los proyectos de tokens de IA de repente tienen un camino hacia costos unitarios sostenibles. V4 está licenciado por MIT y es de peso abierto, lo que significa que cualquiera con GPUs puede alojarlo por sí mismo. Eso elimina el bloqueo del proveedor y se alinea con la tesis de composabilidad de las criptomonedas.
El hardware también forma parte de la historia. Huawei anunció soporte completo para V4 en sus chips Ascend 950 el mismo día. DeepSeek validó el modelo tanto en GPUs Nvidia como en NPUs Huawei Ascend. La compañía dijo que los precios de Pro podrían caer drásticamente una vez que los supernodos Ascend 950 se desplieguen a escala en la segunda mitad de 2026. Una pila de IA doméstica china — modelos más chips — reduce aún más los costos y disminuye la dependencia del hardware estadounidense.
3. Los compromisos
V4-Pro no es el mejor en todo. En SWE-bench Pro, que mide la ingeniería de software en el mundo real, Opus 4.7 lidera con un 64.3% frente a V4-Pro con un 55.4%. En tareas de razonamiento profundo, GPT-5.5 todavía tiene ventaja. DeepSeek reconoce que “las limitaciones en la capacidad de computación de alto nivel” están restringiendo el rendimiento de Pro en su lanzamiento.
Y hay un contexto regulatorio: el Departamento de Estado de EE. UU. advirtió globalmente sobre la supuesta destilación china de modelos de IA estadounidenses un día antes del lanzamiento de V4. OpenAI y Anthropic han acusado a DeepSeek de destilar sus modelos. DeepSeek no ha respondido a esas acusaciones.
4. Qué pasa después
1. Pilotos empresariales: Se espera que los CFO vuelvan a ejecutar modelos de ROI. Si V4-Pro entrega el 95% de la capacidad por el 10% del costo, “suficiente” será la opción ganadora para muchas tareas. 2. Impulso de código abierto: Con 1.6 billones de parámetros, licencia MIT y pesos de Hugging Face, V4 se convierte en el modelo abierto más grande disponible. La afinación y los despliegues privados serán más fáciles. 3. Diversificación del hardware: El soporte completo para Ascend indica que la pila de IA de China está madurando. Si Huawei produce en volumen, los desarrolladores chinos podrán construir sin Nvidia. 4. Respuesta de precios: Observa a OpenAI, Anthropic y Google. Mantener el precio mientras un modelo abierto alcanza un 80.6% en SWE-bench a 1/9 del costo no es un equilibrio estable.
Esta es una guerra de precios, pero también un cambio de estrategia. DeepSeek V4 no afirma superar a GPT-5.5 o Claude Opus 4.7 en todos los puntos de referencia. Afirma estar lo suficientemente cerca, ser abierto y mucho más barato. Durante los últimos dos años, la suposición era que los modelos frontera requerían presupuestos frontera. V4 rompe ese vínculo.
Si la adopción sigue el precio, entonces la demanda de inferencia, el uso de agentes y las aplicaciones integradas de IA — incluidos los tokens de IA en cripto — se expandirán. Los competidores tendrán que responder en costo, no solo en capacidad. Y la narrativa de que la IA avanzada debe ejecutarse en chips estadounidenses acaba de tener un contraejemplo.
La guerra de IA ya no se trata solo de quién tiene el modelo más inteligente. Se trata de quién hace que la inteligencia sea asequible.