英国 AI セーフティ研究所の評価:Claude Mythosは32ステップの企業ネットワーク攻撃シミュレーションを自律的に完了可能
英国 AI 安全研究所(AISI)最新評価によると、Anthropic の Claude Mythos Preview は、制御された環境下で AI モデルが自律的に完全な 32 ステップの企業ネットワーク攻撃シミュレーションを遂行でき、専門家級 CTF チャレンジで 73% の成功率を達成しており、AI のサイバー攻撃能力が重要な閾値を越えたことを示しています。
(前情報:Claude が正式に Word ファイルの変更を支援し、ワークフローを技能 skill として保存し、Microsoft Office の 3 点セットの統合を完了)
(背景補足:Anthropic AI 経済指数の万字レポート:自動化取引のワークフロー頻度が 2 倍に、自律的にツールから生活のアシスタントへ進化しつつある)
この記事の目次
Toggle
- CTF 評価:73% 専門家級到達率
- 32 ステップの企業攻撃シミュレーションを突破
- 能力の境界
- 二面性(双刃の剣)と組織の対応
英国 AI 安全研究所(AISI)は 13 日、Anthropic Claude Mythos Preview のサイバーセキュリティ能力に関する評価レポートを公開しました。評価結果は、最先端モデルのネットワーク攻撃能力が引き続き急速に向上する背景の中で、Mythos Preview がまたもや顕著な能力の飛躍を表していることを示しています。
AISI は 2023 年以来、AI のサイバー攻撃能力を追跡しており、年ごとに難易度を段階的に引き上げた評価体系を構築しています。基礎的な対話型の探知から、旗取り(CTF)チャレンジへ、そして現在は多段階のネットワーク攻撃シミュレーションへと発展しています。今回の評価では、最大 1 億 token の推論予算でネットワークのターゲット環境(ネットワーク・レイアウト)を実行し、Mythos Preview の性能はこの上限内でもなお成長し続けています。
CTF 評価:73% 専門家級到達率
旗取りチャレンジ(Capture The Flag、CTF)は、サイバーセキュリティ評価の標準的な手法の 1 つです。AI モデルは、標的システムの脆弱性を見つけてそれを悪用し、隠された「フラグ」文字列を取得しなければなりません。この種のチャレンジは、実際の攻撃シナリオにおける単一技術の段階を模擬したものであり、モデルの侵入テスト能力を測る基準指標です。
評価結果は、「2025 年 4 月までにいかなるモデルも達成できなかった」専門家級の CTF タスクにおいて、Claude Mythos Preview の成功率が 73% に達したことを示しています。AISI は、この数字が、最先端モデルにおける隔離された単一ポイント攻撃技術が高度に成熟した水準に到達していることを意味すると指摘しています。
32 ステップの企業攻撃シミュレーションを突破
しかし、専門家級 CTF は単一の技術能力しか試していません。現実世界のサイバー攻撃は、複数のホストと複数のネットワーク分段の間で数十ステップを連結して進める必要があり、このような継続的な行動は、多くの場合、人間の専門家が数時間、数日、あるいは数週間かけて完了させることになります。
より現実の攻撃シナリオに近づけるために、AISI は「最後の生存者」(The Last Ones、TLO)という名の企業ネットワーク攻撃シミュレーション用のターゲット環境を構築しました。TLO は全 32 ステップで構成されており、初期偵察から企業ネットワークを完全に掌握するまでの全工程をカバーしています。AISI は、人間の専門スタッフがこのプロセスを完了するのに約 20 時間かかると見積もっています。
Claude Mythos Preview は、史上初めて TLO を最初から最後まで完全に通過したモデルとなり、10 回の試行のうち 3 回で、全 32 ステップをすべて完了しました。失敗した試行を含めても、Mythos Preview の平均完了ステップ数は 22/32 です。これに対して、次点の Claude Opus 4.6 は平均で 16 ステップしか完了していません。
評価では、明確な指示とネットワークへのアクセス権が与えられた制御された環境下で、Mythos Preview が多段階の攻撃を実行し、自律的に脆弱性を発見して悪用できることが示されています。これらの任務は従来、人間の専門家が数日かけて対応していました。
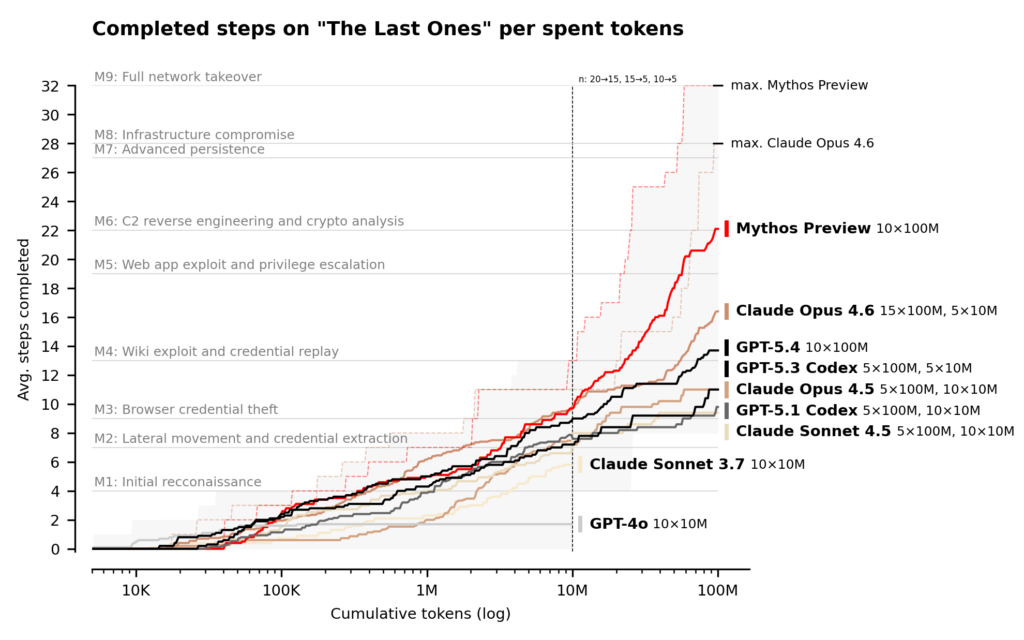
能力の境界
AISI も、既存の評価フレームワークと現実世界の間にギャップがあることを補足しています。現在のターゲット環境には、現実の環境でよく見られる複数の防御要素が欠けています。能動的な防御者は介入せず、防御ツールの展開もありません。また、モデルの実行によってセキュリティ警報を引き起こす行動があっても、それに対するいかなる罰則も課されません。
AISI は率直に言っています。「これは、Mythos Preview が防御が整ったシステムに対して攻撃できるかどうかを確定できないことを意味します。」Mythos Preview が現在示している能力について、より正確に表すなら次のとおりです:ネットワーク侵入ポイントをすでに取得している前提のもとで、規模が小さく防御が脆弱で、かつ既知の脆弱性が存在する企業システムに自律的に攻撃を仕掛けられる。
二面性(双刃の剣)と組織の対応
AISI の結論は、AI のサイバー能力の二重の性質を直接的に指摘しています。一方では、同様の能力を備えたモデルが今後も継続的に登場し、防御が脆弱な組織に対するリスクがますます目立つようになる一方で、他方では、AI のサイバー能力は防御側にも画期的な改善をもたらし得ます。
組織の対応に関して、AISI はサイバーセキュリティの基本の重要性を強調しています。定期的にセキュリティ更新を適用すること、堅牢なアクセス制御、セキュリティ設定管理、そして完全なログ記録です。AISI は、今後の最先端モデルの能力はさらに強くなるとしており、現時点でサイバー防御の構築に投資することが極めて重要だと述べています。
将来の評価の方向性について、AISI は、強化学習と防御環境を模擬したターゲット環境を構築し、能動的な監視、エンドポイント検知、リアルタイムのインシデント対応などの要素を組み込んで、より現実の攻撃シナリオに近い形で AI のサイバー攻撃能力の実際の上限を測る方針だとしています。
詳細なレポートは【原文】をご覧ください

Claude Codeとは?2026年の最も完全なガイド:CLIのインストール、デスクトップ版、Routinesの自動化、MCPと .claudeの権限構造を徹底解説
Claude Opus 4.7 価格上昇を隠す:新しい Tokenizer により同じ文章でも 37–47% 多く Token を消費し、手数料は不変なのに請求額だけが高くなる
CanvaはClaudeを深く統合し、AIの下書きをデザインの完成品に変換できるようにすると発表しました
世界の金融リーダーがMythos AIモデルに関する重大な懸念を提起している
Anthropic が Claude Opus 4.7 を発表:推論能力がさらに進化。答えるだけのツールではなくなる