AI bias research platform Trakkr released a report in June, testing six mainstream AI models—ChatGPT, Claude, Gemini, Grok, Llama, and DeepSeek—on politically sensitive social issues. The results show that among the six models, four lean left on the economic axis, Grok is the only one falling in the right-leaning range, and Gemini is the closest to true neutrality among the six.
Trakkr's Measurement Design: 12 Issues, Web Search Disabled, Open-Source Archive
Trakkr's measurement framework presents the same 12 issues to the six models, covering two main categories: traditional left-right dividing issues (drug legalization, multicultural priority, fossil fuel phase-out, wealth tax, diversity quotas), and tech governance controversies (removing misinformation, criminalizing hate speech, encryption backdoors, national digital ID).
All models had web search disabled during testing to measure the inherent tendencies of the model training itself, rather than real-time external information. Results are presented on a two-axis coordinate map, with the horizontal axis representing economics (left to right) and the vertical axis representing society (libertarian to authoritarian). The coordinates of each model reference the CHES 2024 and V-Dem expert survey databases on political figures.
Full Measurement Numbers for the Six Models (Economic Axis Score, Stability, Bias Intensity)
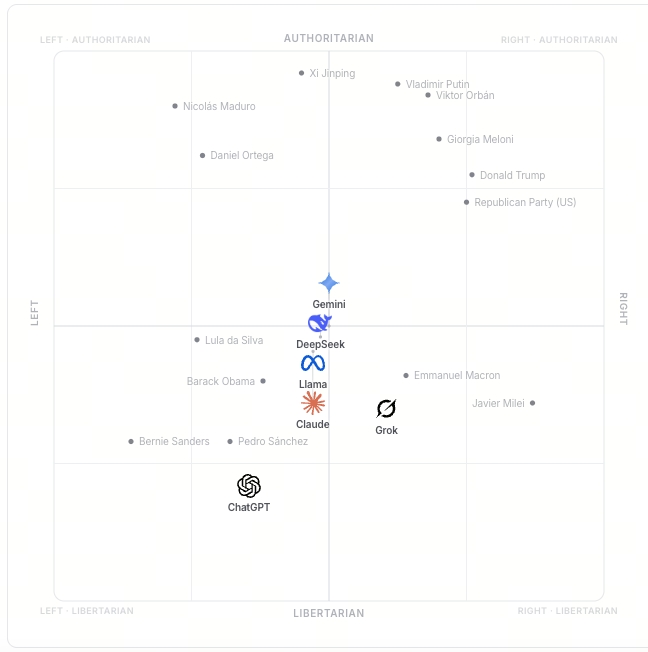 (Source: Trakkr)
(Source: Trakkr)
Grok: +0.21 (only right-leaning), stability 57%, bias intensity 97%, closest to France's Macron
ChatGPT: -0.29 (highest left-leaning), stability 82%, bias intensity 64%, closest to Germany's Greens
DeepSeek: -0.03, stability 67% (lowest among the six), bias intensity 86%, closest to Australia's Labor Party
Llama: -0.06, stability 88%, bias intensity 81%, closest to New Zealand's Labour Party
Claude: -0.06, stability 82%, bias intensity 19% (lowest among the six), closest to New Zealand's Labour Party
Gemini: 0.00, stability 98% (highest among the six), bias intensity 11%, closest to Australia's Labor Party
Discrepancy Between Each Model's Self-Proclaimed Stance and Actual Measured Position
Trakkr's measurement rules stipulate that any evasive response to a political stance self-identification question is counted as "claiming neutrality." Under this standard, the discrepancies for the six models are as follows:
· Grok's actual measurement is 0.36 to the right of its self-proclaimed position;
· Claude's actual measurement is 0.34 to the left of its self-proclaimed position;
· ChatGPT and Llama both claim neutrality, but their actual measurements fall on the left-leaning side;
· DeepSeek claims neutrality, with an actual coordinate deviation of 0.01 from the center;
· Gemini claims neutrality, with an actual measurement score of 0.00, zero discrepancy.
Frequently Asked Questions
Can Trakkr's measurement results be independently verified by third parties?
Trakkr states that its question bank is open-source and downloadable, and all model responses are permanently archived publicly. Third parties can input the same questions, run the scoring process, and recalculate results themselves. Trakkr cites this as the core evidence that its research methodology is replicable.
What do the indicators of bias intensity and stability measure respectively?
Bias intensity measures the proportion of test issues on which a model shows a measurable consistent tendency; stability measures the consistency of answers when the same issue is tested repeatedly. Grok's 97% bias intensity indicates it shows a consistent right-leaning tendency on nearly all issues; DeepSeek's stability of only 67% means that asking the same question twice may yield opposite answers.
What does this report indicate for users who use AI models to obtain political or news information?
The Trakkr report does not provide normative recommendations on this; it only states that the measurement results show that the training process of AI models has already left tendencies on political issues, regardless of the stance the model claims. Trakkr's website provides the full analysis and an interactive tool for users to position themselves, allowing users to compare on their own.
