Título original: A grande estratégia de 10 trilhões de USD da DeepSeek
Autor original: @bookwormengr
Tradução: Peggy, BlockBeats
Nota do editor: No último ano, as discussões em torno da DeepSeek se concentraram principalmente no desempenho do modelo, na estratégia de código aberto e na guerra de preços. Mas, se apenas entender a DeepSeek como uma questão de "vender ou não assinaturas", "ter multimodalidade" ou "fazer um agente de codificação", talvez esteja subestimando o que ela realmente deseja mudar.
Este artigo apresenta um julgamento mais audacioso: o objetivo da DeepSeek talvez não seja monetizar a curto prazo através da camada de aplicação, mas, por meio de uma série de inovações na arquitetura fundamental, reformular a estrutura de custos do treinamento e inferência de IA, e indiretamente impulsionar a formação de um novo ecossistema de hardware. Desde MoE, MLA até DSA, CSA, mHC, Engram, passando por Dual Path e TileLang, a trajetória tecnológica da DeepSeek sempre gira em torno de uma questão central: diante de limitações de HBM, processos avançados, encapsulamento e ecossistema CUDA, como rodar modelos mais poderosos com menos poder de cálculo de ponta.
O aspecto mais interessante do artigo não é se a DeepSeek pode ganhar bilhões de dólares com API ou assinaturas, mas se ela está realmente vinculando a capacidade do modelo, o sistema de memória e o ecossistema de hardware nacional. A compressão do KV Cache reduz a dependência de HBM, NAND e SSD podem suportar cache de longo prazo, LPDDR pode ser usada para carregamento em fluxo de pesos e armazenamento de Engram, e TileLang tenta enfraquecer a barreira do CUDA. Se essas inovações continuarem a se espalhar, os beneficiários não serão apenas a própria DeepSeek, mas também os setores de armazenamento, ASICs, GPUs, chips de rede e toda a cadeia de infraestrutura de IA.
Claro, as avaliações sobre a "indústria de 10 trilhões de dólares" e a "valoração de 1 trilhão de dólares" ainda carregam forte tom de especulação. Mas oferecem uma importante via de compreensão da DeepSeek: abrir o código não significa necessariamente abandonar a comercialização, e preços baixos não são apenas subsídios ao mercado. Para a DeepSeek, o verdadeiro negócio pode não estar na camada de aplicação, mas em ajudar a tornar mais acessível o hardware, possibilitando uma oferta de IA de menor custo. Em outras palavras, ela talvez não venda o modelo em si, mas a viabilidade da próxima geração de infraestrutura de IA.
A seguir, o texto original:

Você já pensou em como a DeepSeek realmente vai ganhar dinheiro, e talvez muito dinheiro?
Ela não lançou um plano de assinatura de programação competitivo como GLM, MoonShot ou MiniMax; também não possui modelos multimodais, de áudio ou vídeo. Até agora, ela nem tem seu próprio sistema de orquestração, ou seja, uma estrutura de execução externa para chamadas de modelos, integração de ferramentas e tarefas — embora recentemente tenham começado a contratar para montar esse sistema.
Ao mesmo tempo, a DeepSeek parece manter uma posição firme no código aberto, até mesmo compartilhando abertamente seus "segredos". Isso não é loucura? Não seria um desperdício de dinheiro? Aquelas pessoas que estão dispostas a investir 100 bilhões de dólares nela, estão jogando dinheiro no ralo?
Na minha opinião, exatamente o contrário.
A seguir, apresentarei algumas observações baseadas no que a DeepSeek já fez até agora, e analisarei uma estratégia que parece estar seguindo. O objetivo do CEO da DeepSeek, Liang Wenfeng, pode ir muito além da competição por modelos. Talvez ele esteja mirando um prêmio maior: a DeepSeek tem a oportunidade de atingir uma avaliação de 1 trilhão de dólares, ao mesmo tempo em que impulsiona a formação de uma nova indústria de 10 trilhões de dólares.

Reportagem do TechInAsia sobre a última rodada de financiamento da DeepSeek
Revendo a "Jornada do Herói" da DeepSeek
A DeepSeek sempre enfrentou ventos contrários. Ela não optou por lançar modelos um pouco mais fortes e rapidamente empacotá-los como aplicações monetizáveis, como planos de assinatura de programação. Em 27 de janeiro de 2025, postei um tweet bastante divulgado, contando a "Jornada do Herói" da DeepSeek na minha visão. Agora, essa história ficou ainda mais interessante.
Enquanto outros ainda tentam construir modelos densos, a DeepSeek escolheu um caminho mais difícil: o de modelos especialistas híbridos (Mixture of Experts, MoE).
Eles adotaram uma abordagem de "primeiro princípio", inventando um novo algoritmo chamado GRPO, para substituir o então popular, mas mais caro, algoritmo de reforço PPO.
Descobriram que o reforço baseado em recompensas verificadas (Reinforcement Learning from Verified Rewards, RLVR) é a estratégia-chave para melhorar a capacidade de inferência do modelo.
Também propuseram uma estratégia de decodificação simples chamada "Multi Token Prediction" (Previsão de Múltiplos Tokens), que torna o sinal de treinamento mais denso.
Aperfeiçoaram a linha de produção "Zero Bubble" (ZERO bubble) para melhorar a eficiência do uso de recursos limitados de GPU.
Lançaram um balanceador de carga de especialistas, facilitando a implantação de modelos MoE. Especialmente com a estratégia de "Wide Expert Parallel" (Paralelismo de Especialistas Amplos), o modelo pode atender a lotes maiores, reduzindo drasticamente o custo de inferência.
Inventaram mecanismos como MLA, DSA, CSA, HCA, para reduzir a dependência do KV Cache, e manter o aumento do custo de cálculo com o crescimento do comprimento do contexto o mais próximo possível de constante.
Criaram o Engram, trocando memória por eficiência de cálculo.
E também desenvolveram o mHC, que permite treinar modelos de grande escala de forma estável. Existem muitos outros exemplos semelhantes.
Na narrativa do "Jornada do Herói", o herói nunca decide de início para onde sua jornada irá. Ele aprende ao longo do caminho, descobrindo sua verdadeira missão, e, apesar de obstáculos, a realiza. Enfrenta céticos, ignora-os. Enfrenta malfeitores. Tem falhas e limitações, mas as supera. Enfrenta desafios aparentemente impossíveis, encontra aliados e aprende a usar recursos escassos de forma inteligente. É essa trajetória que faz o público torcer por ele. E é por isso que a DeepSeek conquista seguidores, respeito global e opositores.
Como detalharei a seguir, a DeepSeek já percorreu esse caminho há bastante tempo, e vem descobrindo seu destino final: seu objetivo não é vender assinaturas de programação, mas impulsionar um ecossistema de hardware de IA de 10 trilhões de dólares na China, e alcançar uma avaliação de 1 trilhão de dólares. Nesse processo, ela também criará oportunidades para novos entrantes no ecossistema de hardware ocidental.

Começando por alguns cálculos interessantes de KV Cache
Veja a recente postagem oportuna do @SemiAnalysis_:
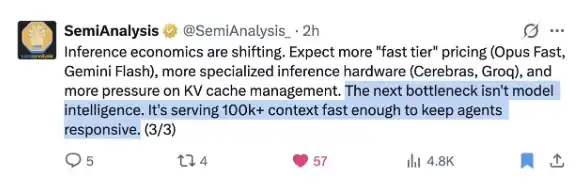
A DeepSeek já resolveu esse problema melhor do que qualquer outro!
Vamos fazer um cálculo interessante de KV Cache. Não se preocupe, mesmo que você não goste de matemática, tudo bem. Usaremos o calculador de KV Cache recém-lançado para ver quanto a DeepSeek V4 Pro pode economizar de KV Cache, comparando com os modelos mais recentes da GLM e Qwen.
Farei o cálculo considerando um contexto de cerca de 1 milhão de tokens, assumindo uma precisão de KV de 8 bits e de indexador de 16 bits. Você também pode experimentar o calculador por si mesmo: https://kvcache.ai/tools/kv-cache-calculator/
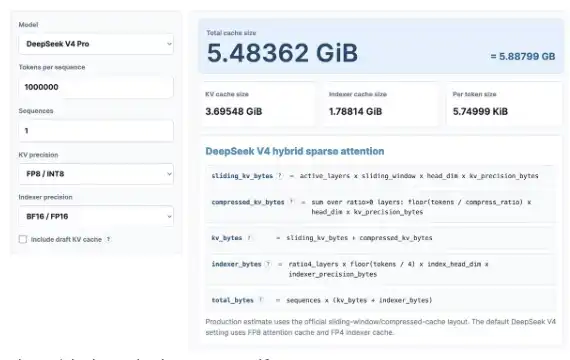
Você também pode experimentar o calculador por si mesmo!
Para um contexto de cerca de 1 milhão de tokens:
· DeepSeek V4 precisa de apenas 5,48 GB de HBM;
· GLM-5 necessita de 60 GB de HBM;
· Qwen3-235B-A22B chega a precisar de até 89 GB de HBM.
É importante notar que:
· DeepSeek é um modelo de 1,6 trilhão de parâmetros;
· GLM-5 tem cerca de 700 bilhões de parâmetros, já usando MLA e DSA do DeepSeek, embora ainda sem a mais recente atenção comprimida;
· Qwen3-235B-A22B tem aproximadamente 235 bilhões de parâmetros, usando mecanismo GQA de atenção.
Na questão de aliviar a pressão de memória, a DeepSeek já deu uma contribuição fundamental. Se essas inovações forem amplamente adotadas, reduzirão significativamente o custo de operação de agentes de longo ciclo e desbloquearão novos cenários de aplicação.
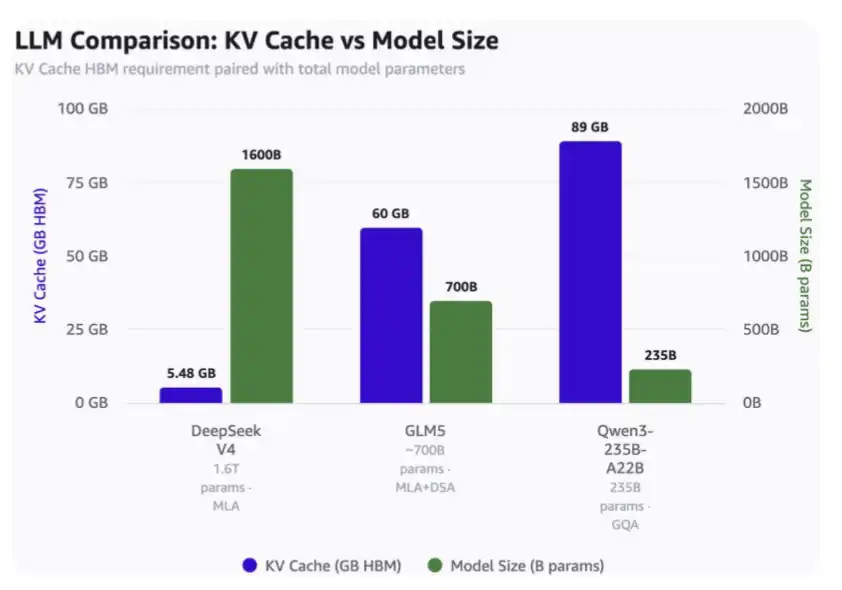
Comparativo de uso de KV Cache em contextos de 1 milhão de tokens e diferentes tamanhos de modelo
A metodologia por trás da "loucura"
A razão de o KV Cache poder ser tão compacto, sem sacrificar a qualidade do modelo, é que a DeepSeek consegue oferecer cache de longo prazo a preços extremamente baixos — menos de 3% do custo de cache hit do Sonnet 4.6, e ainda pode manter o cache por horas.
Para tarefas de longo ciclo, um KV Cache menor significa que é mais econômico descarregá-lo para SSD e recarregá-lo quando necessário. Assim, a dependência de HBM diminui. Do ponto de vista da indústria de hardware de IA na China, o HBM não só é escasso, como também uma das memórias mais difíceis de fabricar.
Além disso, a DeepSeek desenvolveu tecnologia para carregar KV Cache do SSD de forma mais rápida, já descrita em seu artigo sobre Dual Path.
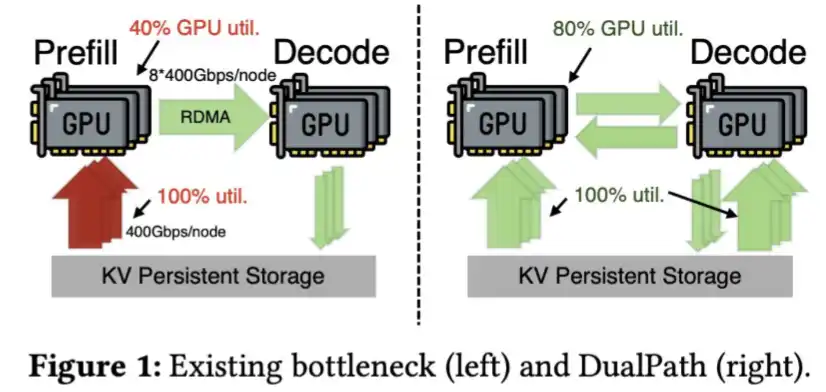
A compressão do KV Cache na DeepSeek V4 é tão significativa que talvez essa etapa nem precise mais ser feita.
Quem se beneficia mais diretamente da compressão do KV Cache?
Quem fornece SSD em larga escala? Não se esqueça, a YMTC (Yangtze Memory Technologies) está se consolidando como uma gigante no setor de NAND 3D. NAND ajuda a evitar cálculos repetidos de KV, e, por sua vez, a DeepSeek cria um enorme mercado para NAND e SSD — beneficiando não só a YMTC, mas também outros fabricantes relacionados.

Porém, não se trata apenas de NAND e SSD.
A memória LPDDR também tem potencial enorme. Pode armazenar os pesos do modelo e transmiti-los em fluxo para o HBM quando necessário, aliviando a pressão sobre o HBM. A equipe do SGLang publicou um excelente blog explicando essa abordagem. A imagem abaixo mostra como ela funciona.
Embora a DeepSeek não tenha feito um design específico para essa estratégia, sua arquitetura MoE, a presença de muitos especialistas e o uso de pesos de 4 bits facilitam a implementação dessa solução.
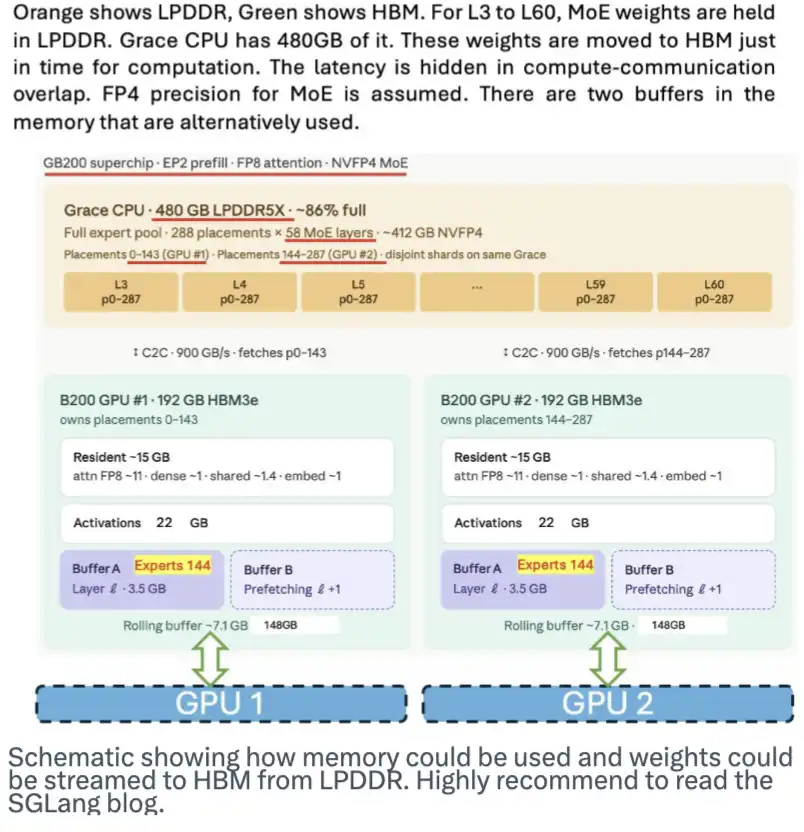
A imagem mostra como a memória pode ser usada e como os pesos do modelo podem ser transmitidos em fluxo do LPDDR para o HBM. Recomendo fortemente a leitura do blog do SGLang.
Se essa inovação for combinada com um KV Cache extremamente compacto e sem perdas, a demanda por HBM será drasticamente reduzida.
Quem na China produz LPDDR? A resposta é a CXMT, ou seja, a Changxin Memory Technologies. Eles estão cerca de meia geração atrás em velocidade de LPDDR, uma geração atrás em densidade, mas a diferença não é grande.
Além de NAND suficiente, o ecossistema de IA na China também terá acesso a LPDDR suficiente em um futuro próximo. Isso pode aliviar a pressão de cálculo? A resposta é: sim. Continue lendo.

Memória inteligente também pode aliviar a pressão sobre GPUs / ASICs
Usar NAND para armazenar KV Cache é bastante intuitivo: permite que o KV Cache seja mantido por mais tempo, reduzindo a dependência do HBM, além de evitar cálculos repetidos de KV, aliviando a carga de GPUs e ASICs.
E a LPDDR pode desempenhar papel semelhante? Além de atuar como armazenamento "on-demand" para transmitir pesos ao HBM, ela pode reduzir ainda mais a carga de cálculo?
A resposta é: sim.
LPDDR pode armazenar uma grande quantidade de conteúdo chamado Engram. No artigo do Engram da DeepSeek, eles apontam que o MoE pode expandir a capacidade do modelo por cálculo condicional, mas o Transformer, por si só, carece de um mecanismo nativo de "busca de conhecimento". Assim, ele precisa simular ineficientemente esse processo por cálculo.
Para resolver isso, a DeepSeek propôs o módulo Engram. Ele moderniza o embedding N-gram clássico, transformando-o em um mecanismo de busca baseado em hash com O(1), criando uma via esparsa complementar, chamada memória condicional.
Essa abordagem economiza cálculo, mas requer memória para abrigar a tabela de embedding, que pode ser muito grande.
Basicamente, é uma solução de "troca de memória por cálculo". A chave está no fato de que, do ponto de vista do custo de leitura de cada bit de dado, a memória é muito mais barata — uma busca em LPDDR é muito mais econômica do que passar os dados por várias camadas de Transformer para uma única inferência. Portanto, em cenários de grande escala, essa troca é altamente vantajosa.
Essa é a estratégia da DeepSeek: sacrificar parte da memória para economizar cálculo.
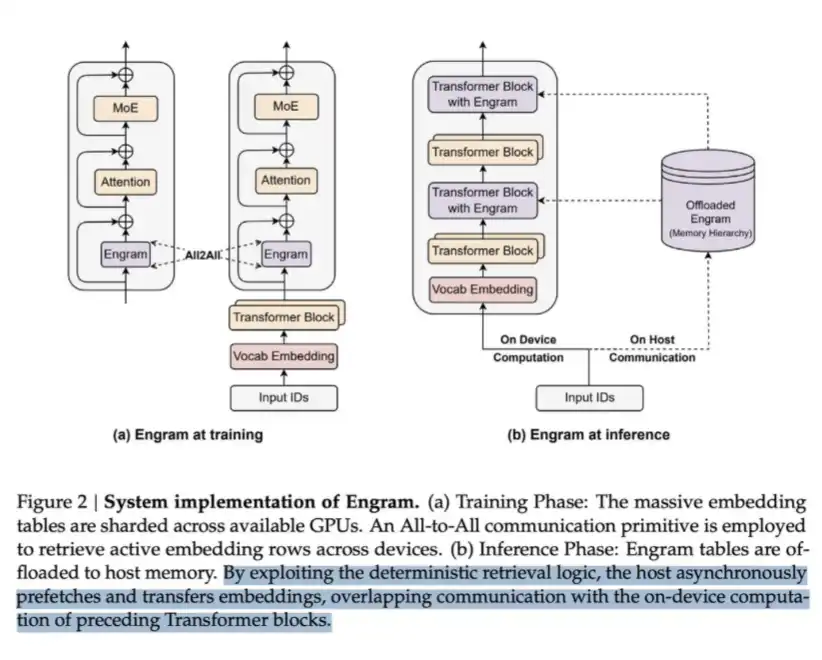
Escolhas que valem a pena
Sem transistores de nível equivalente ou tecnologia EUV, os GPUs e ASICs chineses provavelmente ficarão por muito tempo atrás dos ocidentais em termos de FLOPs brutos. Ainda há uma clara defasagem em encapsulamento avançado. Portanto, essas escolhas valem muito a pena, especialmente considerando a capacidade da China de produzir NAND e LPDDR em grande escala.
Revisando a estratégia de longo prazo da DeepSeek
Com base nessas inovações, parece que o objetivo da DeepSeek não é obter lucros de alguns bilhões de dólares no curto prazo. Muitas de suas decisões até agora indicam isso: ela ainda não possui multimodalidade, nem modelos de voz ou vídeo.
O que ela realmente participa é de um jogo de longo prazo, paciente, potencialmente de 10 trilhões de dólares: impulsionar a formação de um ecossistema de hardware de IA alternativo.
Isso não é apenas para fazer com que fabricantes chineses de memória se tornem atores-chave no mercado de hardware de IA na China e globalmente, mas também para reduzir fundamentalmente os recursos necessários, tornando o treinamento e o serviço de modelos de IA mais econômicos. Assim, muitos fabricantes de GPUs, ASICs e chips de rede terão opções viáveis.
Ao mesmo tempo, essas inovações beneficiarão também o ecossistema de código aberto ocidental e novos fabricantes de hardware.
Todos esses sinais já estão presentes. Vamos revisar detalhadamente as inovações que a DeepSeek propôs até agora:
- Introdução do modelo híbrido de especialistas (MoE) e MLA na DeepSeek V2
Na versão 2, a DeepSeek introduziu MoE e MLA. MoE reduz em cerca de 40% a 50% o cálculo necessário para treinar modelos de alta inteligência; MLA diminui o KV Cache em 90%.
Isso torna a transferência do KV Cache para SSD bastante eficiente.
Essas ideias surgiram inicialmente no artigo da DeepSeek de maio de 2024, que marcou a versão 2. Depois, também fundamentaram o treinamento da versão 3. Na época, a DeepSeek treinou um sistema com apenas 2048 GPUs H800, com desempenho próximo ao de modelos fechados.
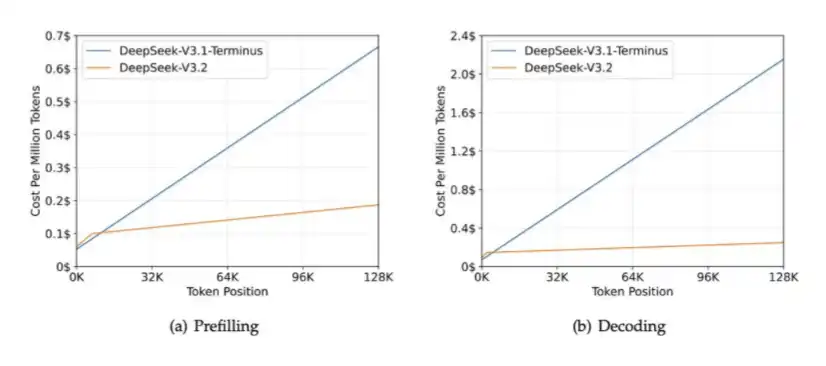
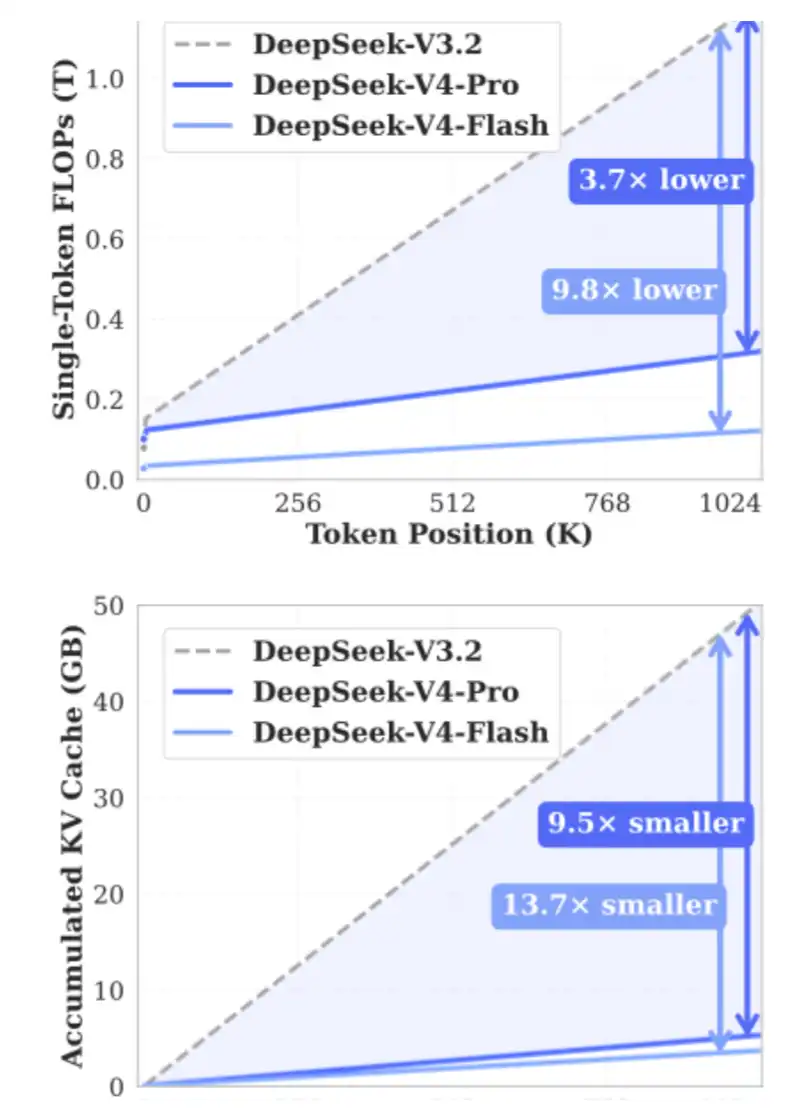
- DSA: introduzido na versão 3.2 experimental, para reduzir o custo de cálculo em contextos de longo alcance, além de aliviar a pressão na largura de banda do HBM.
O papel principal do DSA é garantir que o volume de cálculo não cresça com o aumento do comprimento do contexto. Veja o gráfico abaixo: com o aumento do comprimento do contexto, o tempo de processamento do DeepSeek-V3.2 permanece praticamente estável.
- mHC: proposto em dezembro de 2025, no artigo "mHC: Manifold-Constrained Hyper-Connections".
O mHC é uma inovação na arquitetura macro da DeepSeek, que redesenha o fluxo de informações entre as camadas do Transformer.
Tradicionalmente, desde ResNet, os modelos usam conexões residuais padrão, ou seja, x + F(x). O mHC expande esse fluxo de resíduo para múltiplos canais paralelos, permitindo que o modelo aprenda a misturar esses canais. O ponto-chave é que a matriz de mistura é restrita a uma matriz dupla-aleatória, limitada ao poliedro de Birkhoff via projeção Sinkhorn-Knopp. Assim, matematicamente, garante-se que, independentemente da profundidade, a amplitude do sinal permaneça estável.
Isso resolve o problema de instabilidade catastrófica enfrentado por conexões hiper-espaciais não restritas. Originalmente proposto pelo ByteDance, sem restrições, o sinal de hiper-conexões pode explodir, chegando a 3000 vezes o valor original em modelos de 270 bilhões de parâmetros, levando ao colapso do treinamento.
O custo computacional do mHC é baixo: cerca de 6,7% do tempo de treinamento real, pois não altera as FLOPs das camadas de atenção ou FFN, apenas muda a forma como suas saídas são roteadas entre camadas.
Por outro lado, o desempenho melhora significativamente: em 270 bilhões de parâmetros, o mHC aumenta em 7,2 pontos a precisão na tarefa de inferência BIG-Bench Hard, 3,2 pontos na DROP, 2,8 pontos na tarefa matemática GSM8K, e 1,4 pontos na tarefa de conhecimento geral MMLU. Essas melhorias ocorreram com o mesmo tamanho de modelo e quase o mesmo orçamento de cálculo.
Na essência, o mHC fornece uma topologia de roteamento de informações entre camadas mais expressiva, permitindo maior inteligência por parâmetro, sem aumentar significativamente as FLOPs.
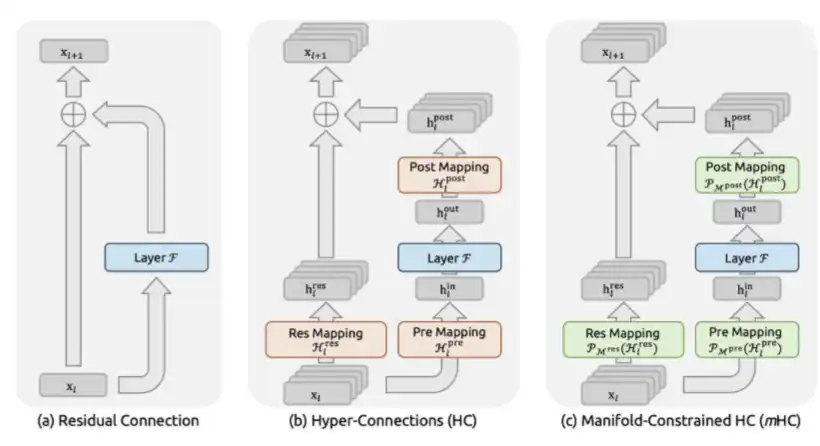
O mHC é uma arquitetura complexa, mas traz maior estabilidade no treinamento e maior inteligência por parâmetro.
- CSA, HSA: introduzidos na versão 4, em abril de 2026.
CSA e HSA visam reduzir em 90% a demanda por KV Cache, comprimindo ainda mais o uso de KV tokens, além de diminuir drasticamente as FLOPs necessárias, aliviando tanto o HBM quanto GPUs/ASICs.
- Engram: introduzido no primeiro trimestre de 2026, essencialmente usando memória — ou seja, LPDDR — para trocar por eficiência de cálculo.
A figura detalhada abaixo mostra que, com o mesmo orçamento de parâmetros, o Engram proporciona melhorias de desempenho notáveis.
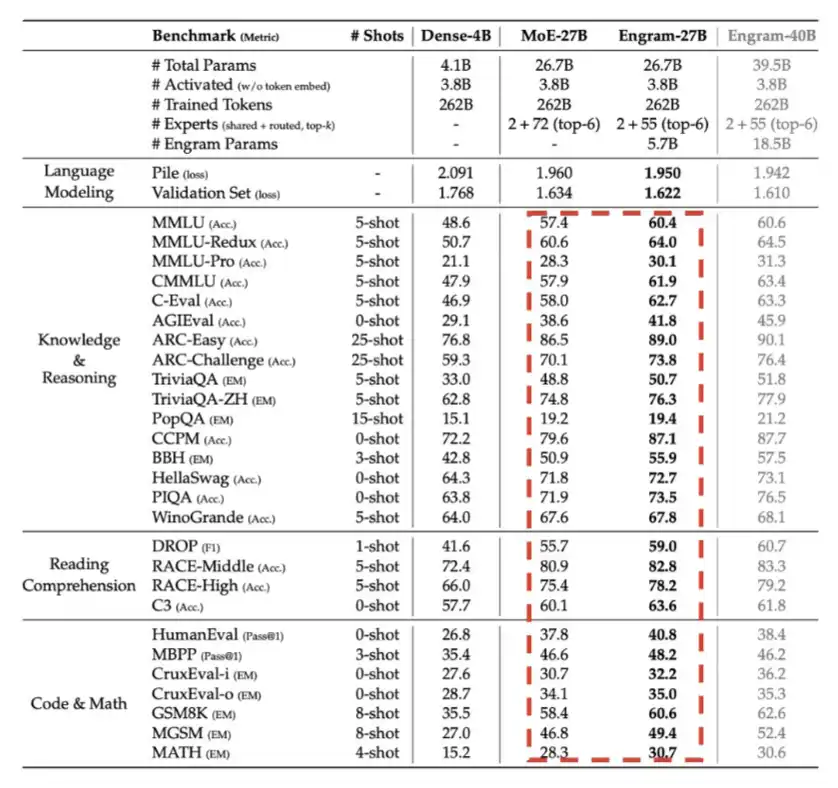
- Engram: introduzido no primeiro trimestre de 2026, usando memória — LPDDR — para trocar por eficiência de cálculo.
A mesma figura mostra que, com o mesmo orçamento de parâmetros, o Engram melhora significativamente o desempenho.

Essa é uma recomendação da DeepSeek para fabricantes de hardware, compartilhada na versão 4 do artigo. Tenho certeza de que, em conversas presenciais, eles darão ainda mais detalhes.
O investimento em TileLang também aponta para o mesmo objetivo: a DeepSeek não está apenas resolvendo seu gargalo de cálculo, mas impulsionando a capacidade do ecossistema de hardware chinês de competir com o ocidental.
Com TileLang, desenvolvedores podem escrever uma única kernel — ou seja, o código de baixo nível para cálculo — e fazê-lo funcionar em várias plataformas de hardware, desde que tenham suporte ao backend TileLang.
Prevejo que outros laboratórios chineses de IA também se juntem a essa iniciativa. Isso ajudará fabricantes chineses de hardware a enfrentarem indiretamente a barreira do "CUDAS". Além disso, também potencializará o hardware ocidental, como a AMD.
Vale destacar que muitas plataformas de hardware de IA na China já oferecem compatibilidade com CUDA ou camadas de tradução. Exemplos incluem Moores, Muxi, Biren e Tiannanshi, que usam camadas de tradução para alta compatibilidade com CUDA. Portanto, teoricamente, elas podem não precisar de TileLang.

Aprendizado por reforço em larga escala e RSI
À medida que a DeepSeek obtém mais fontes de poder de cálculo, ou seja, mais opções de hardware, e à medida que a demanda por recursos computacionais do modelo diminui, ela pode avançar para projetos de treinamento mais ambiciosos, especialmente de reforço.
Reforço exige gerar muitas trajetórias, ou seja, trilhões de tokens. Esse processo se torna extremamente caro rapidamente. Além disso, para treinar modelos com contexto de 1 milhão de tokens, é preciso gerar trajetórias do mesmo comprimento. Somente treinando em trajetórias superlongas é possível suportar tarefas de longo ciclo.
Além disso, com mais opções de hardware, os recursos disponíveis para a DeepSeek aumentam, impulsionando a pesquisa automatizada, ou RSI. RSI refere-se a IA que projeta e executa seus próprios experimentos. Essa abordagem envolve tentativa e erro, cujo custo pode subir rapidamente. Mas, antes de alcançar a AGI, e depois a ASI, a DeepSeek precisa desenvolver capacidades de RSI.
O que a DeepSeek faz hoje, o setor todo seguirá amanhã
As inovações da DeepSeek em áreas como modelos híbridos de especialistas, MLA, DSA, já vêm sendo adotadas por outros laboratórios de IA ao redor do mundo e na China.
Por exemplo, a equipe por trás do modelo GLM, a ZAI, usa MLA e DSA. Kimi, do MoonShot, também adotou MLA e declarou abertamente que sua arquitetura é baseada na estrutura da DeepSeek. Por sua vez, a DeepSeek usa o otimizador Muon, que foi inicialmente utilizado pelo Kimi em treinamentos de grande escala.
Cabe esclarecer:
MoE foi originalmente proposto pelo Google em 2017, com o principal autor sendo Noam Shazeer. A contribuição da DeepSeek foi aplicar em larga escala o MoE e inventar suas próprias técnicas complementares.
Muon, ou seja, o otimizador MomentUm Orthogonalized by Newton-Schulz, foi proposto por Keller Jordan, pesquisador de aprendizado de máquina, no final de 2024. A equipe do Kimi (MoonShot) foi a primeira a usá-lo em treinamentos de grande escala.
E quanto a ganhar dinheiro?
Vamos olhar um exemplo interessante: a OpenAI.
A OpenAI obteve opções de compra de ações de AMD e Cerebras a preços baixos, vinculadas a marcos de consumo de poder de cálculo. Para AMD e Cerebras, essa foi uma negociação muito vantajosa, pois, ao comprometerem-se a usar seus hardwares, aumentam muito as chances de sucesso a longo prazo.
No anúncio da AMD, há uma frase:
"Como parte do acordo, para alinhar ainda mais os interesses estratégicos, a AMD emitiu opções de compra de até 160 milhões de ações ordinárias da AMD para a OpenAI, que serão adquiridas gradualmente conforme o cumprimento de marcos específicos. A primeira parcela será adquirida ao completar a implantação inicial de 1 GW, e as demais à medida que a escala de aquisição atingir 6 GW. As condições de aquisição também dependem de metas de preço de ação específicas da AMD e do alcance de marcos tecnológicos e comerciais necessários para a implementação em larga escala pela OpenAI."

Prevejo que a DeepSeek também firmará acordos semelhantes com várias fabricantes chinesas de memória, ASICs, CPUs e stacks de tecnologia de rede, colaborando profundamente para que esses hardwares possam suportar cargas de trabalho de ponta em IA.
Considerando que o valor de mercado de ações de IA no Ocidente, incluindo aliados do Leste Asiático, já ultrapassa 10 trilhões de dólares, essa estratégia de "obter retorno acionário por meio de cooperação" pode ajudar a China a construir uma indústria igualmente gigante, conquistando sua fatia do bolo e, por fim, atingindo sua avaliação de 1 trilhão de dólares.
Isso não só permitirá que a DeepSeek ganhe muito mais do que com assinaturas tradicionais, como também ajudará a realizar seu objetivo de "beneficiar todos com a AGI". Liang Wenfeng é fã de Jim Simons e um investidor inteligente; ele certamente não perderia essa oportunidade.
Se você refletir sobre tudo o que a DeepSeek já fez até agora, essa é a explicação mais coerente.
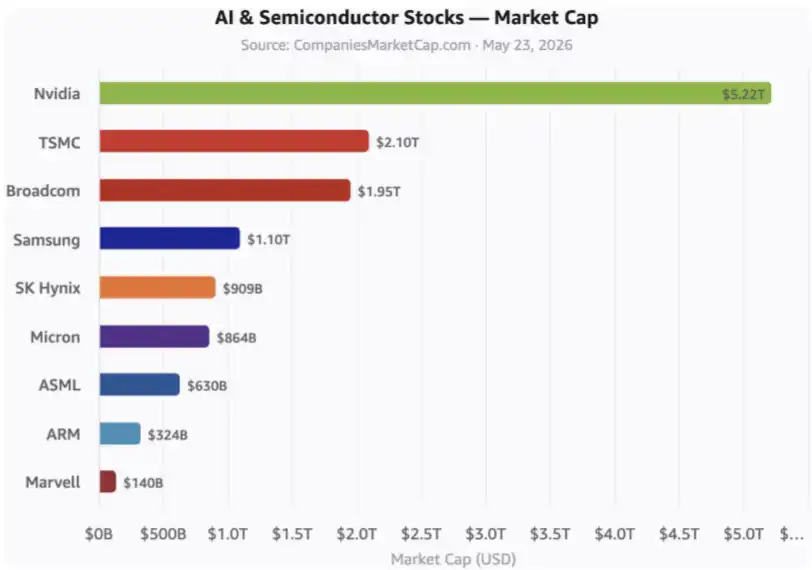
Esses são os principais papéis no mercado de ações de IA. Os hyperscalers, ou seja, os gigantes de nuvem, e muitas outras empresas relacionadas, ainda não estão incluídos na imagem.
[Link do original]
Clique para conhecer as vagas do Rhythm BlockBeats
Participe do grupo oficial do Rhythm BlockBeats no Telegram:
Telegram assinatura: https://t.me/theblockbeats
Telegram grupo de discussão: https://t.me/BlockBeats_App
Conta oficial no Twitter: https://twitter.com/BlockBeatsAsia
