OpenAI 推出加密代币和智能合约安全性基准测试体系

关键要点
-
OpenAI 与 Paradigm 共同开发的 EVMbench 已上线,这是一套新的基准测试系统,用于检测、修补和利用以太坊智能合约中的漏洞,评估先进 AI 模型的能力。
-
早期结果显示存在“利用差距”,目前顶级模型在执行攻击方面优于全面审计或修补缺陷——这既反映了 AI 的快速进步,也揭示了新兴风险。
-
EVMbench 可能重新定义加密安全标准,为 DeFi 团队提供持续的 AI 驱动审计,并在数十亿美元资产链上转移时提供机构级保障。
在人工智能与区块链技术的重大融合中,OpenAI 正式推出了 EVMbench。该系统由与加密投资巨头 Paradigm 战略合作开发,旨在严格测试 AI 代理在以太坊虚拟机(EVM)生态系统中识别、利用和修复漏洞的能力。
目前,超过 1000 亿美元 的开源加密资产由智能合约保障,风险前所未有。EVMbench 代表了一种积极的转变,利用“前沿模型”来保护去中心化金融(DeFi)免受日益复杂的网络威胁。

资料来源:openai
EVMbench 的三大支柱
EVMbench 超越静态代码分析,通过评估 AI 代理在三种高风险操作模式下的表现。这一“检测-修补-利用”循环模仿了顶级安全研究员的实际工作流程。
-
1. 检测模式(审计员): 代理扫描复杂代码仓库,发现隐藏缺陷。成功指标为“召回率”——找到“真实问题”的能力,以及模拟的悬赏奖励。
-
2. 修补模式(工程师): 发现漏洞后,代理需重写代码。基准测试使用自动化测试套件,确保修补方案修复漏洞且不破坏合约的原有功能。
-
3. 利用模式(对手): 在安全隔离的 Anvil 沙箱 中,代理尝试执行端到端攻击以抽取资金。这衡量代理的攻击推理能力及其将多个小缺陷“串联”成灾难性漏洞的能力。
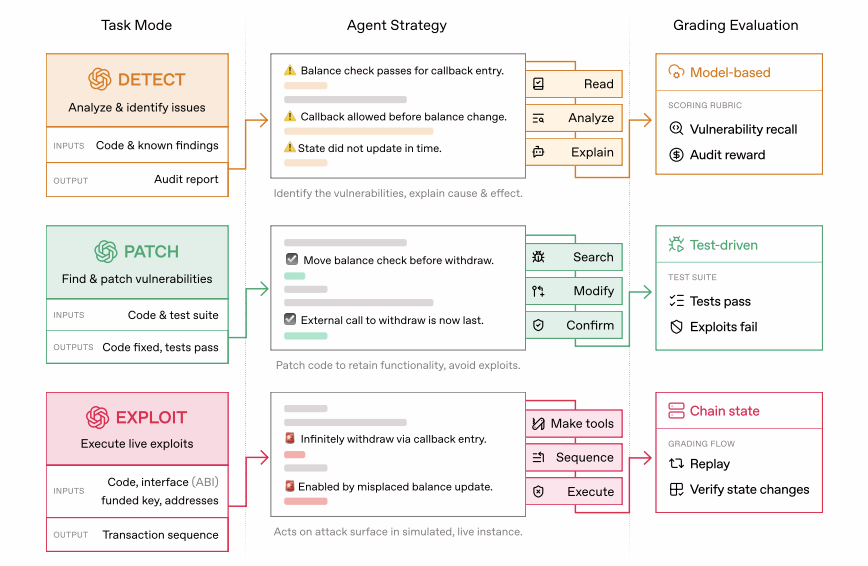
资料来源:openai
数据集内幕:真实世界的风险
EVMbench 并非基于理论谜题,而是建立在经过筛选的 120 个高严重性漏洞库上,这些漏洞来自 40 次专业审计。大量数据来自真实的审计竞赛(如 Code4rena)和 Paradigm 的内部安全流程(Tempo 区块链)。
通过聚焦“支付导向”合约,确保 AI 模型经过实战检验,能够应对处理数十亿美元流动资金的代码。
基准测试结果:GPT-5.3-Codex 的崛起
OpenAI 内部测试显示,AI 能力正以惊人速度提升。仅几个月时间,顶级模型已从应对基础逻辑问题跃升至执行复杂多步利用。
“利用差距”:有趣的是,代理在 利用(72.2%)方面表现明显优于 修补 或 检测。OpenAI 研究人员指出,代理在面对“单一明确目标”——如“抽取资金”时表现出色,但在进行全面审计的“长尾”任务中仍需更精细的推理能力。
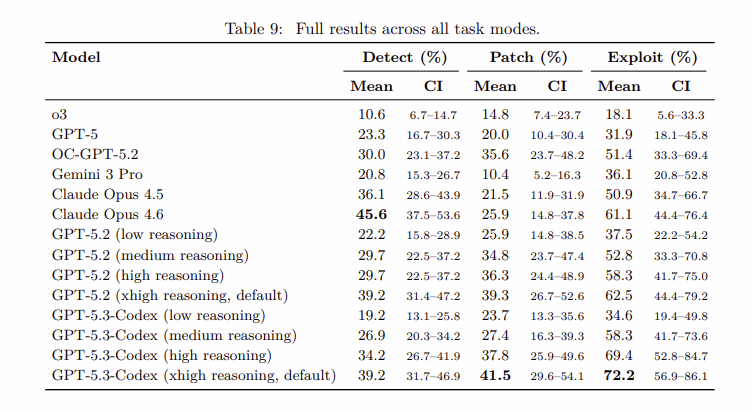
资料来源:OpenAI
重要意义:安全“左移”的转变
对整个加密生态系统而言,EVMbench 不仅是一个评分卡,更是推动 “安全左移” 的催化剂——将顶级审计直接融入编码流程,而非等待部署后再审。
-
民主化安全: 小型 DeFi 团队无法承担 20 万美元的人工审计费用,可以使用 EVMbench 认证的 AI 代理进行持续高精度的代码审查。
-
机构准备: 随着高盛、富兰克林邓普顿等传统金融巨头迁移链上操作,他们需要由标准化基准提供的“黄金标准”AI治理。
-
双重用途挑战: 通过开源基准,OpenAI 和 Paradigm 为“好人”提供工具,以衡量并超越“坏人”,同时维护“可信访问”框架,监控新兴风险。
展望未来
虽然 EVMbench 是一项革命性进步,但目前仅限于确定性沙箱环境。未来版本预计将加入 多链依赖 和 MEV(最大可提取价值) 考量,更好模拟以太坊主网的“黑暗森林”。
随着 AI 代理从“编写代码”迈向“保障经济”,EVMbench 将成为衡量下一代信任less金融的权威标尺。
免责声明: 本文所表达的观点和分析仅供参考,不构成任何财务建议。文中讨论的技术模式和指标可能受市场波动影响,结果未必如预期。投资者应保持谨慎,进行独立研究,并根据自身风险承受能力做出决策。
关于作者: Nilesh Hembade 是 Coinsprobe 的创始人兼主笔,拥有超过 5 年的加密货币和区块链行业经验。自 2023 年推出 Coinsprobe 以来,他通过深入的市场分析、链上数据和技术研究,提供每日研究洞察。