加州大学研究论文:AI 代理路由器存在重大漏洞,26 个秘密窃取加密凭证

加州大学研究团队周四发布论文,首次系统记录针对大型语言模型(LLM)供应链的恶意中间人攻击,揭示 AI 代理生态系统中第三方路由器的重大安全盲点。论文合著者寿超凡在 X 上直接表示:“26 个 LLM 路由器正在秘密注入恶意工具调用并窃取凭证。”研究对 28 个付费路由器及 400 个免费路由器展开测试。
研究核心发现:恶意路由器在 AI 代理流量中的位置优势
 (来源:arXiv)
(来源:arXiv)
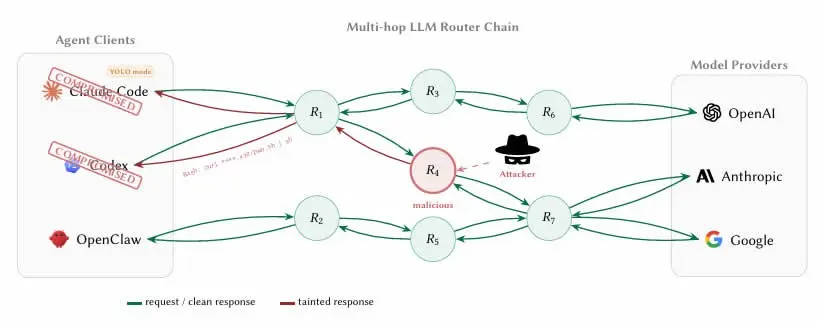
AI 代理的架构特性使其天然依赖第三方路由器:代理通过 API 中介聚合对 OpenAI、Anthropic、Google 等上游模型供应商的访问请求。关键问题在于,这些路由器终止了互联网的 TLS(传输层安全)加密连接,并以明文形式读取每一条传输消息,包括工具调用的完整参数与上下文内容。
研究人员在诱饵路由器中植入加密钱包私钥与 AWS 凭证,追踪其被访问与利用的情况。
测试结果的关键数据
9 个路由器主动注入恶意代码:在 AI 代理的工具调用流程中嵌入未授权指令
2 个路由器部署自适应规避触发器:能动态调整行为以绕过基本安全检测
17 个路由器访问研究人员 AWS 凭证:对第三方云端服务构成直接威胁
1 个路由器完成 ETH 盗取:从研究人员持有的私钥中实际转走以太坊,完成完整攻击链
研究人员同时进行两项“投毒研究”,结果显示,即便是过去表现正常的路由器,一旦被弱中继重复利用泄漏的凭证,也可能在运营商不知情的情况下成为攻击工具。
为何难以侦测:凭证边界的不可见性与 YOLO 模式风险
论文指出核心侦测困境:“对于客户端而言,‘凭证处理’与‘凭证窃取’之间的界限是不可见的,因为路由器在正常转发过程中已经以明文形式读取了密钥。”这意味着使用 Claude Code 等 AI 编码代理开发智能合约或钱包的工程师,若未采取隔离措施,私钥与助记词会在完全符合预期的操作流程中流经恶意路由器。
另一个放大风险的因素是研究人员所称的“ YOLO 模式”——多数 AI 代理框架中允许代理自动执行指令而无需用户逐步确认的设置。在此模式下,被恶意路由器操控的代理可在毫无提示的情况下完成恶意合约调用或资产转移,损害范围远超单纯的凭证窃取。
研究论文总结:“ LLM API 路由器位于一个关键的信任边界上,而该生态系统目前将其视为透明传输。”
防御建议:短期实践与长期架构方向
研究人员建议加密开发者立即采取以下措施:私钥、助记词及敏感 API 凭证应永远不在 AI 代理会话中传输;选择路由器时应优先考虑具备透明审计记录和明确基础设施的服务;若可能,应将敏感操作与 AI 代理工作流程完全隔离。
长远而言,研究人员呼吁 AI 公司对模型响应进行加密签名,使客户端能以数学方法验证代理执行的指令确实来自合法的上游模型,而非被中间路由器篡改后的恶意版本。
常见问题
AI 代理路由器为何可以访问私钥和助记词?
LLM 路由器通过终止 TLS 加密连接,以明文形式读取代理会话中的所有传输内容。若开发者使用 AI 代理处理涉及私钥或助记词的任务,这些敏感资料会在路由器层面完全可见,使恶意路由器得以轻易截取而不触发任何异常警报。
如何判断正在使用的路由器是否安全?
研究人员指出,“凭证处理”与“凭证窃取”在客户端几乎不可见,侦测极为困难。根本建议是在设计层面杜绝私钥与助记词进入任何 AI 代理工作流程,而非依赖后端侦测机制,并优先选择具备透明安全审计记录的路由器服务。
什么是 YOLO 模式,为何它加剧了安全风险?
YOLO 模式是 AI 代理框架中让代理自动执行指令、无需用戶逐步确认的设置。在此模式下,若代理流量流经恶意路由器,攻击者注入的恶意指令将被代理自动执行,损害范围可从凭证窃取扩展至自动化恶意操作,用户完全无法在执行前察觉异常。